Idée centrale
Cette page représente l’état du modèle à un instant donné. Elle ne clôt pas le travail : elle montre comment Foresportia mesure, détecte, corrige et améliore progressivement ses probabilités lorsque les signaux deviennent suffisamment fiables.
La conclusion de la série : mesurer plutôt que promettre
Les cinq premières notes ont décrit les briques de Foresportia : le problème probabiliste, le rôle réel de l’IA, la confiance, le contexte et les marchés de buts. Cette sixième note ferme la boucle : comment évaluer ce système sans tomber dans le marketing ou l’illusion de certitude ?
La réponse est simple dans son principe, mais exigeante dans sa mise en œuvre : comparer à des baselines, mesurer les probabilités avec des métriques adaptées, surveiller le drift, exposer les limites et améliorer le moteur quand les données montrent une faiblesse exploitable.
Les chiffres présentés ici ne sont donc pas une proclamation définitive. Ils décrivent Foresportia à un moment donné. Le programme, son état actuel et ses cycles d’amélioration sont également suivis sur la page IA prédiction football, qui sert de référence publique sur l’évolution du moteur.
1. Une équation globale pour résumer Foresportia
La série entière peut se résumer par une formule volontairement compacte :
Pour un match M, à l’instant t, le moteur transforme plusieurs familles de signaux en sorties probabilistes :
où :
- p̂1X2 représente la distribution domicile / nul / extérieur.
- λHgoals et λAgoals représentent les intensités de buts dédiées au moteur des marchés de buts.
- p̂BTTS et p̂Over/Under décrivent les marchés de buts calibrés.
- C représente une lecture de confiance qui combine probabilité, marge, entropie, historique et contexte.
- B représente le badge produit : Stable, Correct ou Risk.
Le symbole t rappelle que le modèle n’est pas figé. Une probabilité publiée aujourd’hui dépend de la version du moteur,
de la couverture des ligues, de l’historique disponible, des calibrations actives et des signaux de drift détectés.
C’est une représentation à l’instant t, destinée à être vérifiée et améliorée.
2. Ce que chaque note a apporté
3. Baselines : faire mieux qu’une règle naïve
Un modèle n’a de valeur que s’il apporte plus qu’une règle simple. Prédire toujours l’équipe à domicile, suivre le classement ou prendre un favori ELO simplifié donne déjà des repères. Foresportia doit donc être comparé à ces points de référence avant de parler de performance.
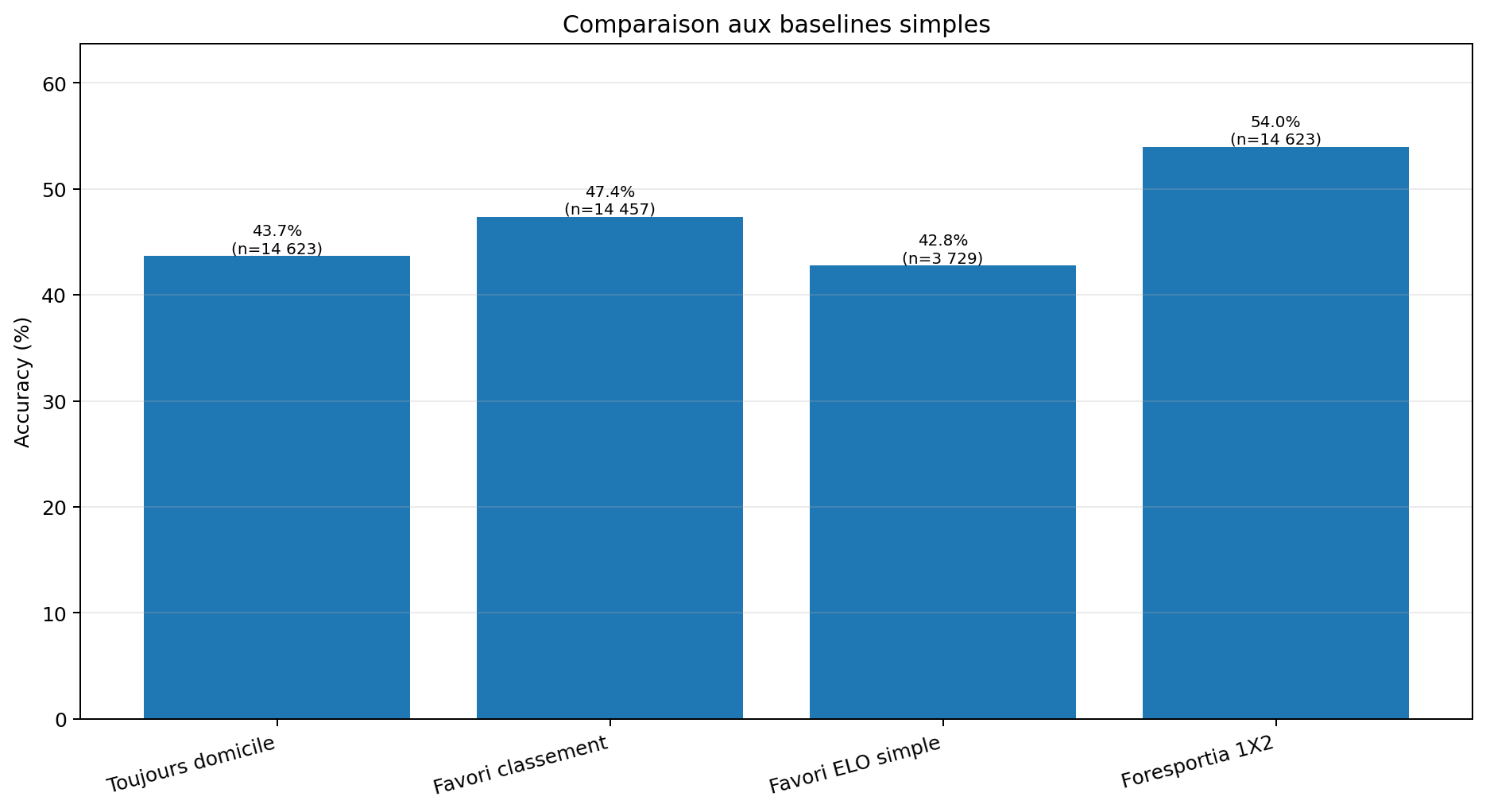
L’accuracy globale de Foresportia est autour de 54.0 % sur ce snapshot. C’est une mesure utile, mais elle ne suffit pas : elle ne dit pas si les probabilités sont bien calibrées, ni si le modèle sait identifier ses propres zones de confiance.
4. Comprendre les métriques : accuracy, Brier score, log loss et ECE
L’accuracy mesure simplement si l’issue la plus probable est la bonne :
Mais une prédiction probabiliste doit être évaluée plus finement. Le Brier score multiclasses mesure l’écart quadratique entre la distribution prédite et le résultat observé :
Dans cette convention, 0 est parfait. Pour trois issues, une prédiction uniforme à 33/33/33 aurait un Brier proche de 0,667. Le score observé ici, environ 0.578, est donc meilleur qu’une probabilité non informative, mais il laisse encore une marge d’amélioration.
La log loss pénalise très fortement les erreurs confiantes :
Une prédiction uniforme sur trois classes donne ln(3) ≈ 1,099. La log loss observée, environ 0.972, indique donc que le modèle porte un signal réel, mais qu’il doit continuer à limiter la surconfiance sur les zones fragiles.
Enfin, l’ECE simplifié mesure l’écart moyen entre confiance annoncée et fréquence observée :
Ici, un ECE autour de 0.061 signifie un écart moyen d’environ 6.1 points entre la confiance et la réussite observée selon les bins. Ce n’est ni catastrophique ni parfait : c’est exactement le type de signal qui sert à piloter les cycles de calibration.
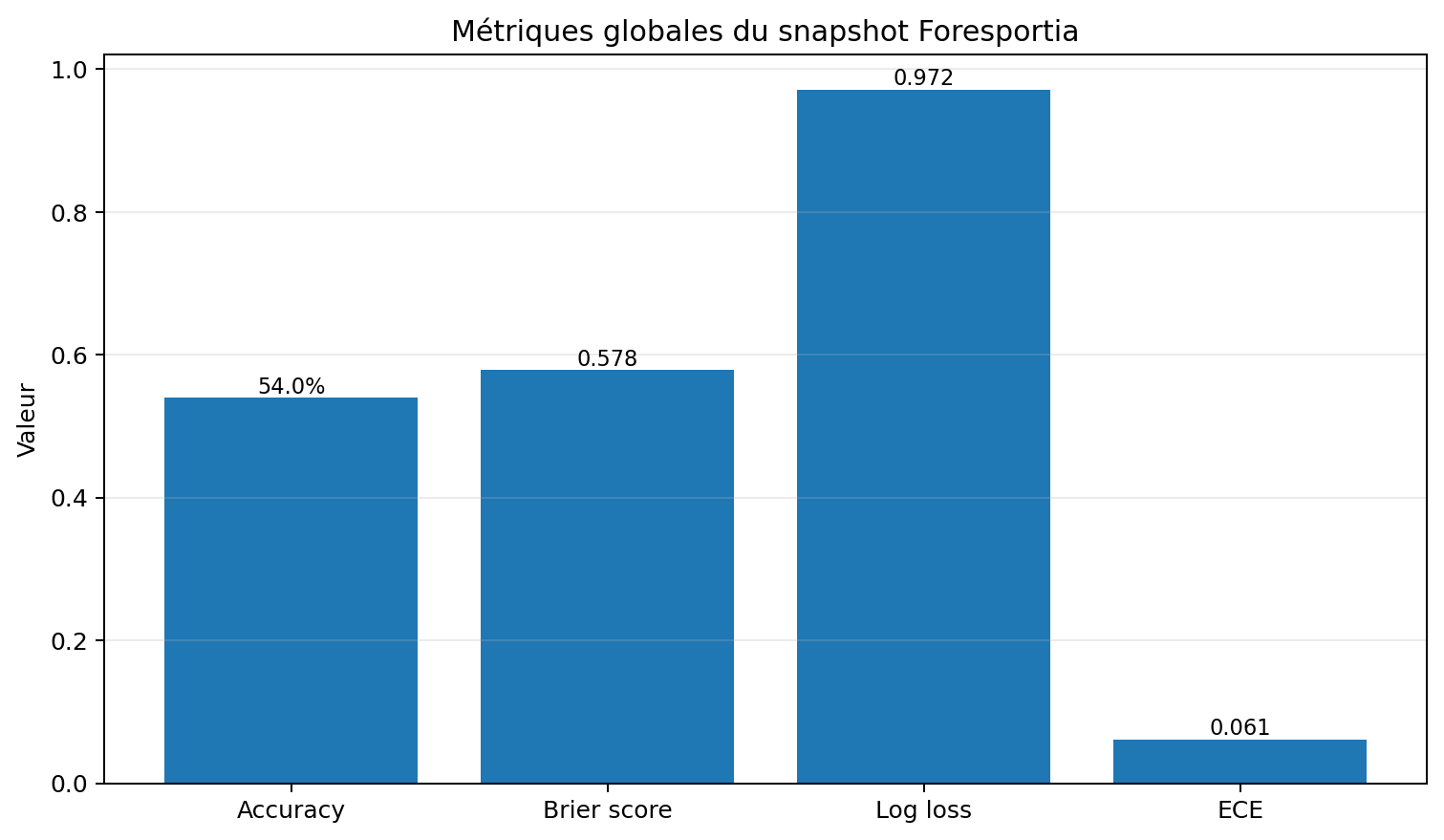
Le Brier score et la log loss sont calculés sur l’ensemble des matchs terminés. Ils incluent donc aussi les matchs les plus incertains, les ligues les plus bruitées et les situations où Foresportia classe volontairement le signal en Risk. Ces métriques sont indispensables pour mesurer la calibration globale, mais elles ne résument pas la valeur produit du modèle.
La force principale de Foresportia est sa capacité à segmenter les matchs : l’accuracy globale tourne autour de 54 %, mais les segments Stable et Correct atteignent des niveaux nettement supérieurs. Le modèle n’est donc pas seulement évalué sur sa moyenne globale ; il est aussi évalué sur sa capacité à identifier les zones où le signal est réellement exploitable.
5. Calibration : une probabilité doit se comporter comme une fréquence
Une probabilité n’a de valeur que si elle se vérifie sur des groupes de matchs comparables. Si un modèle annonce 60 %, on doit tendre vers environ 60 % de réussite observée sur un volume suffisant. Sinon, le modèle est trop confiant ou trop prudent.
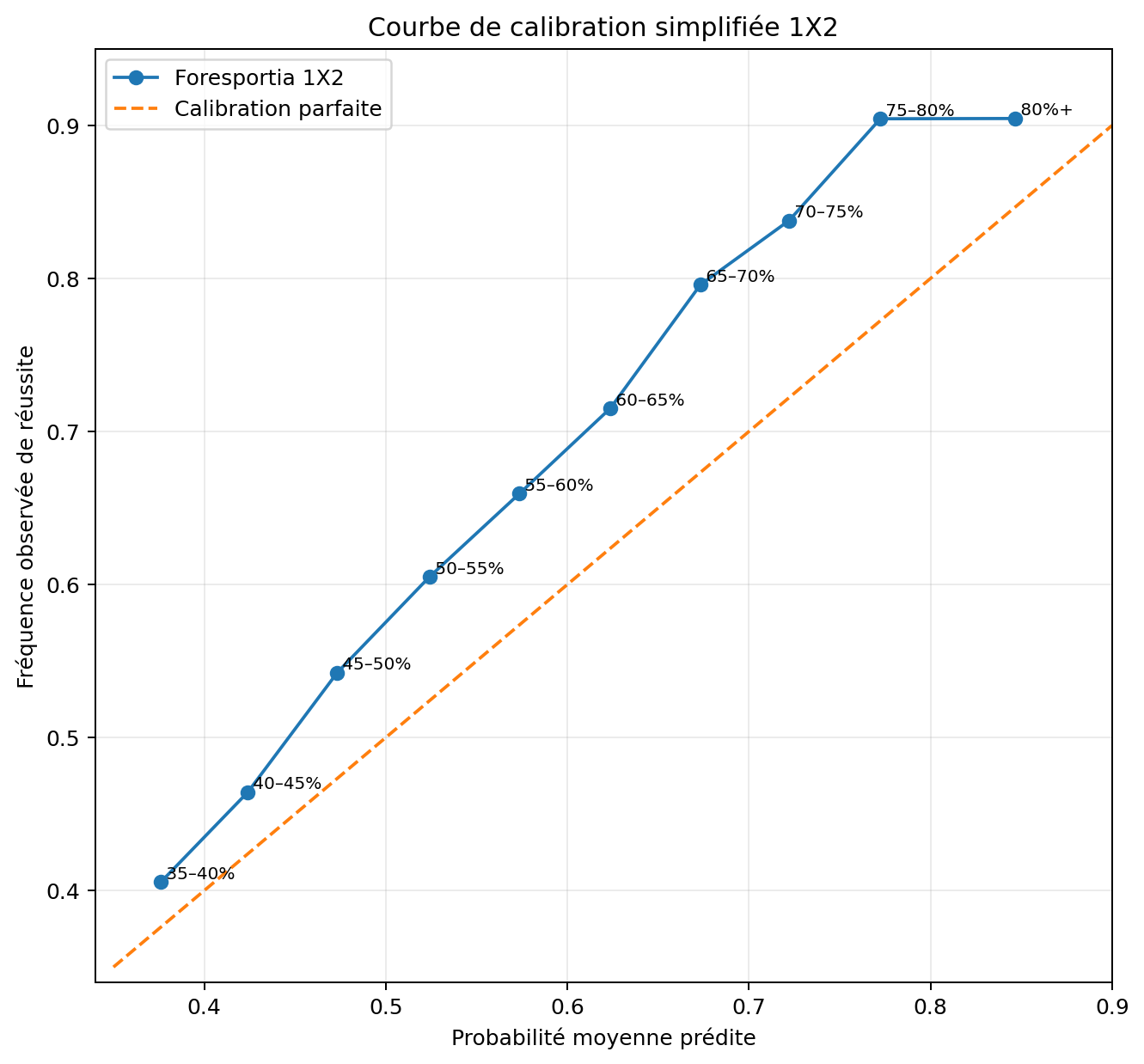
Une bonne accuracy peut cacher une mauvaise calibration. Un modèle peut gagner souvent parce qu’il classe bien les matchs, tout en étant trop confiant sur ses favoris. C’est pour cette raison que Foresportia distingue la probabilité, le score de confiance et le badge de stabilité.
6. Validation par segment : la vraie valeur des badges
Les badges Stable, Correct et Risk n’ont de sens que s’ils correspondent à des différences observables. Sur ce snapshot, le segment Stable + Correct atteint environ 78.5 % d’accuracy, mais ne couvre qu’environ 21.9 % des matchs. Le segment Risk couvre beaucoup plus de volume, avec une accuracy nettement plus basse.
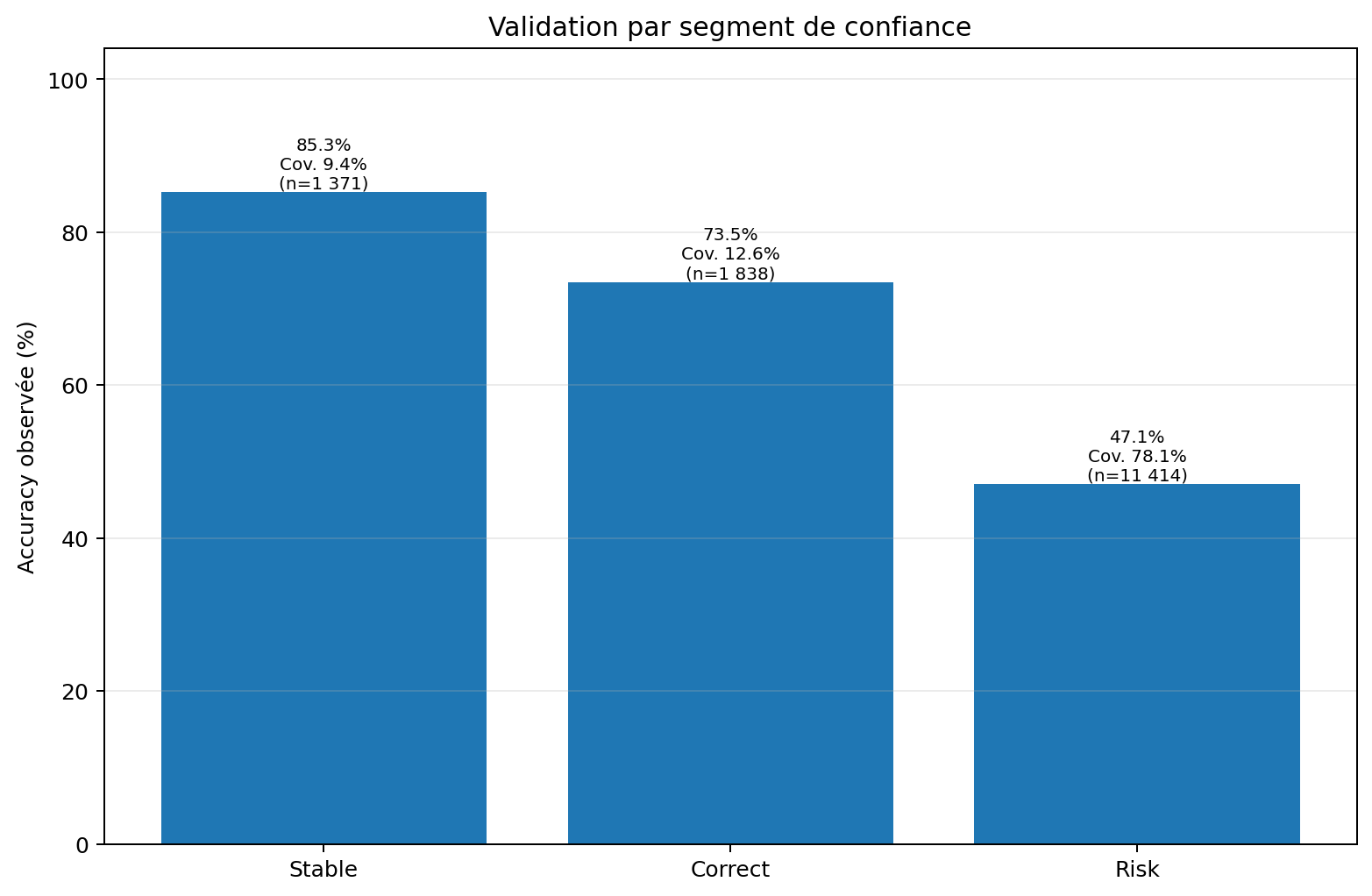
C’est l’un des résultats les plus importants de la série. Le modèle ne cherche pas à rendre tous les matchs jouables ou “sûrs”. Il accepte que la majorité des matchs reste incertaine, puis cherche à isoler les zones où le signal est plus propre.
7. Ligues et hétérogénéité : l’ouverture augmente aussi l’incertitude
Plus Foresportia couvre de ligues, plus le modèle rencontre des distributions différentes : championnats très stables, ligues à forte variance, compétitions avec peu d’historique, calendriers irréguliers ou équipes moins bien observées. Cette diversité est précieuse pour le produit, mais elle augmente mécaniquement la difficulté statistique.
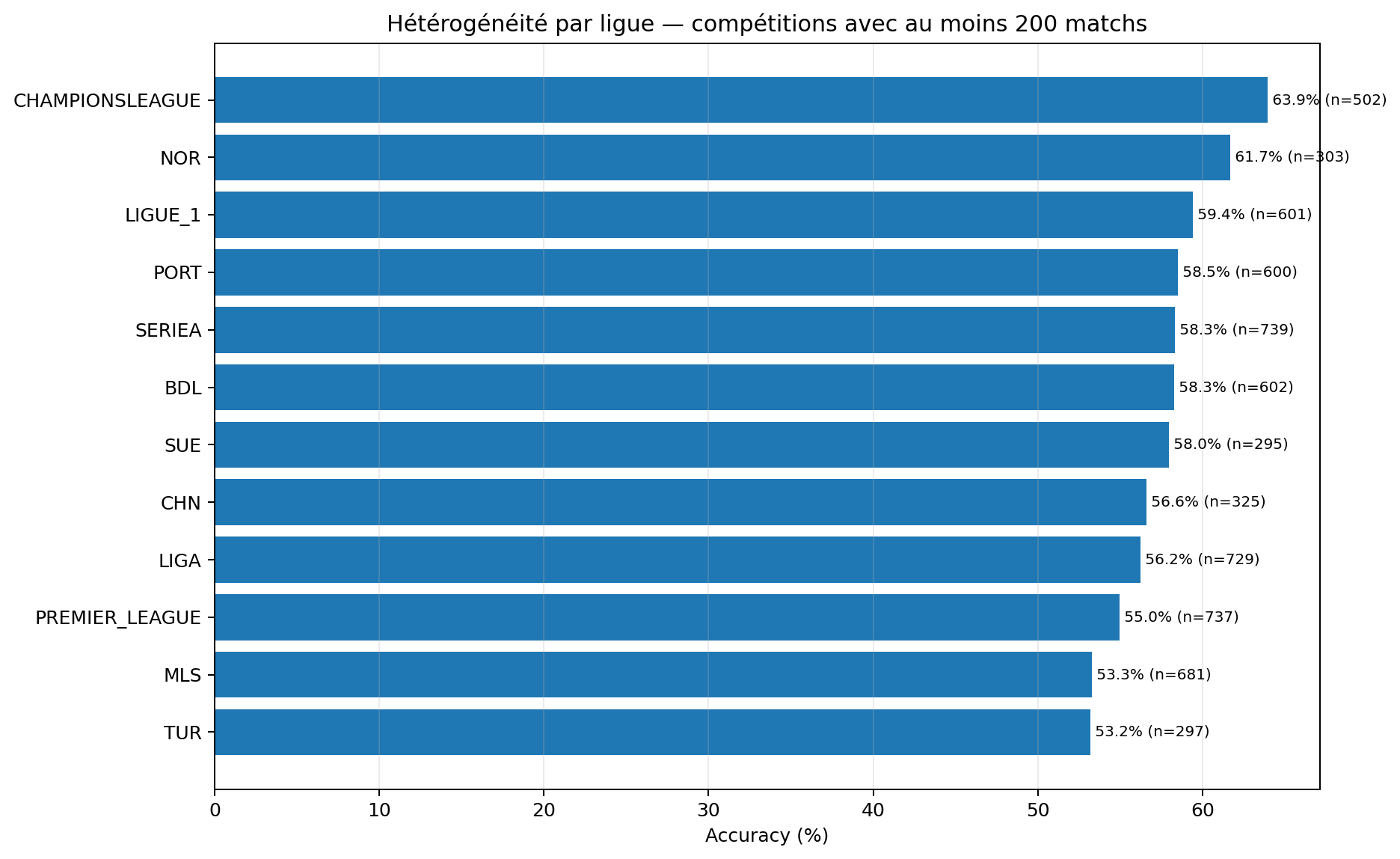
C’est aussi pour cette raison que les pages thématiques comme la Coupe du monde 2026 méritent une attention spécifique : une compétition courte, internationale et à échantillon limité ne se traite pas comme une ligue domestique longue.
8. Drift temporel : une baisse n’est pas seulement un échec, c’est un signal de travail
Le drift désigne une variation de performance dans le temps. Il peut venir d’un changement de saison, d’un changement de moteur, d’un élargissement à de nouvelles ligues, d’un contexte sportif particulier ou d’un déséquilibre temporaire dans les données.
La lecture correcte d’une courbe de drift n’est pas “le modèle est bon” ou “le modèle est mauvais”. La bonne lecture est : où le modèle change-t-il de comportement, et que doit-on corriger ?
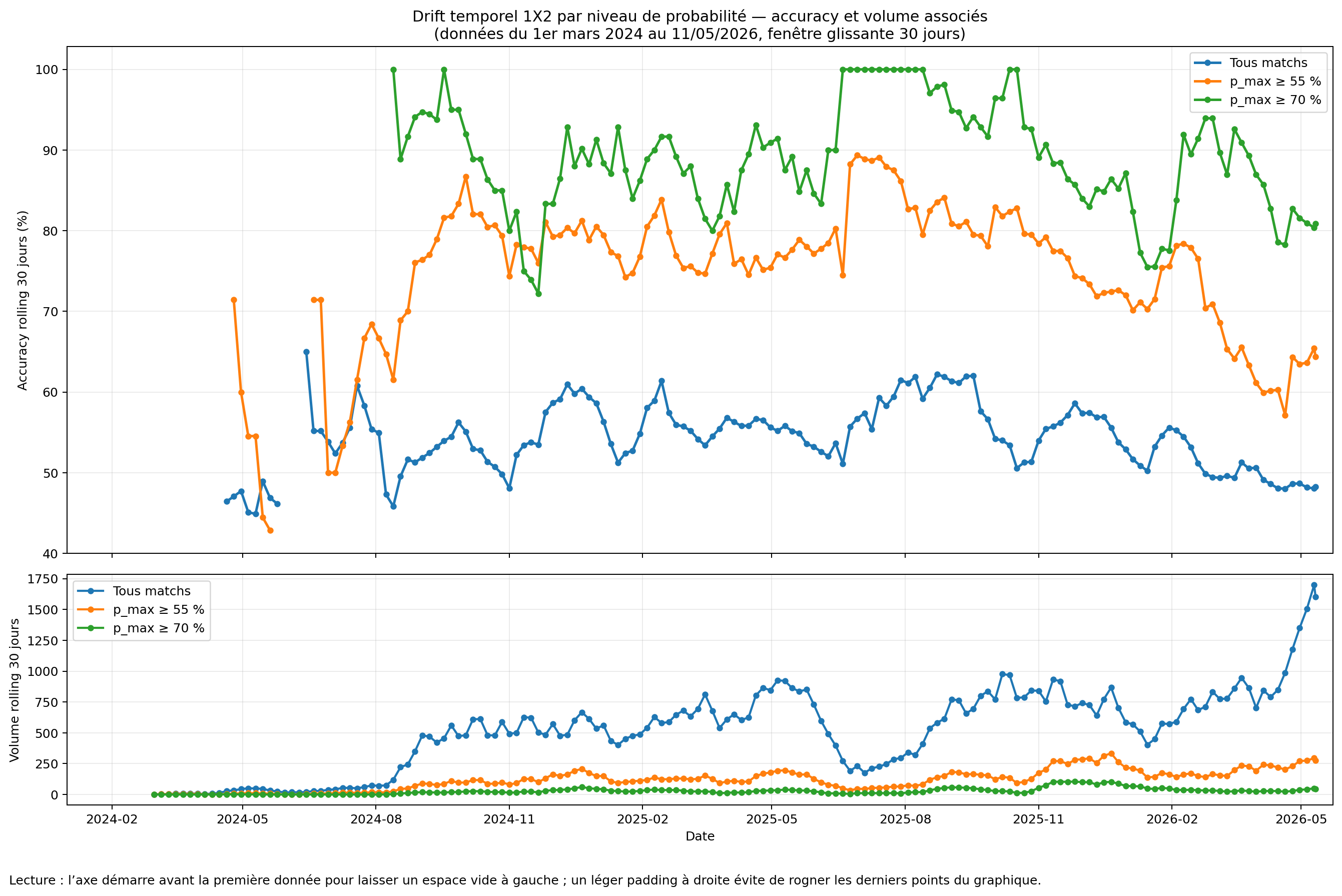
Cette figure présente l’accuracy rolling sur 30 jours, accompagnée du volume de matchs dans la même fenêtre. La lecture du drift devient ainsi plus complète : la baisse globale reflète aussi l’élargissement de la couverture et l’intégration de matchs plus incertains, tandis que les segments à forte probabilité restent nettement au-dessus de la moyenne globale.
Le segment p_max ≥ 70 % conserve une performance élevée, mais repose sur un volume plus faible.
Ses variations de court terme doivent donc être interprétées avec prudence : une baisse sur une centaine de matchs
n’a pas la même signification qu’une baisse observée sur plusieurs milliers de rencontres.
L'ajout de nouvelles ligues va mécaniquement faire baisser les performances du modèle temps que la calibration de ces ligues soient effectuées.
9. Le vrai point fort : un modèle améliorable et partiellement autonome
Foresportia n’est pas seulement un ensemble de formules figées. Le moteur est conçu comme une boucle : prédictions pré-match, résultats terminés, comparaison aux probabilités publiées, détection des zones de drift, recalibration, ajustement des seuils et nouvelle version.
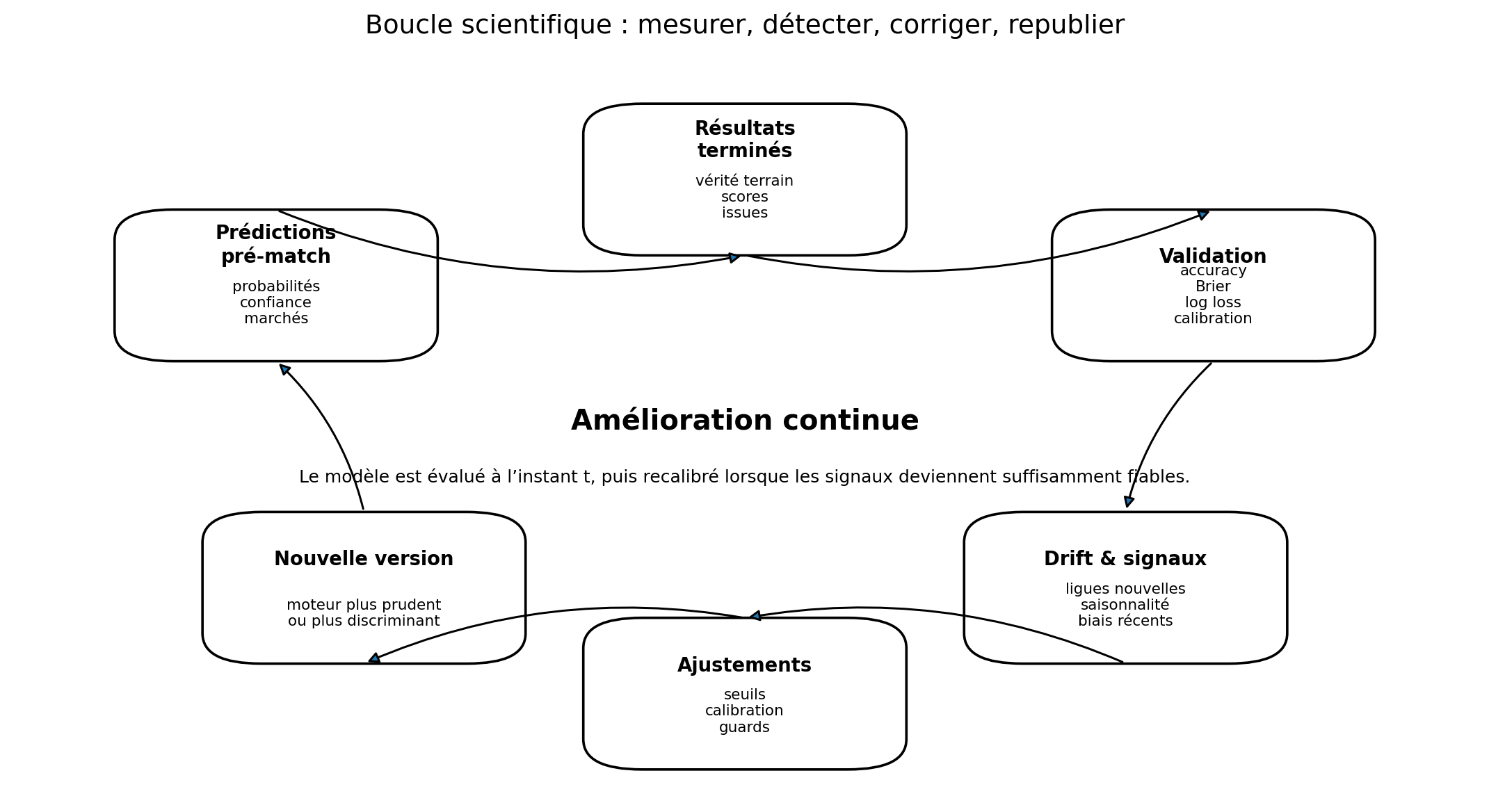
Cette autonomie ne veut pas dire que le modèle change au hasard. Elle signifie qu’il peut réagir lorsque les signaux sont suffisamment fiables : une ligue qui dérive, un seuil trop permissif, un marché de buts trop agressif, une zone de confiance surestimée ou un flag contextuel devenu pertinent.
Cette formule résume l’idée : les paramètres de demain doivent être informés par les erreurs d’aujourd’hui, mais sous contraintes. On ne veut pas sur-réagir à trois matchs isolés ; on veut apprendre lorsque le signal devient robuste.
10. Marchés de buts : une leçon importante de la série
L’article V a montré une décision structurante : ne pas forcer BTTS, Over/Under et scores probables à sortir naïvement de la même grille que le 1X2. Le 1X2 mesure le vainqueur, les marchés de buts mesurent l’intensité du match. Ce sont deux objets liés, mais pas identiques.
C’est une bonne illustration de la philosophie Foresportia : lorsqu’un marché demande une modélisation spécifique, il vaut mieux construire un moteur dédié, calibré et vérifiable, plutôt que préserver une élégance mathématique trompeuse.
11. Pourquoi publier tout cela ?
Cette série n’a pas été écrite pour vendre une promesse de gain. Elle existe parce que la beauté du projet est scientifique : modéliser l’incertitude, construire des probabilités honnêtes, accepter les limites, mesurer les erreurs et améliorer le système.
Foresportia ne propose pas de liens d’affiliation betting, et ce n’est pas un hasard. La valeur recherchée n’est pas de pousser un utilisateur vers un bookmaker, mais de produire une lecture data plus rigoureuse du football. La page À propos explique davantage cette démarche.
Pour ceux qui veulent exploiter les données de manière plus avancée, une page API Foresportia a été ouverte. Et pour les grands événements à venir, comme la Coupe du monde 2026, l’objectif sera de voir comment adapter cette approche à un contexte court, rare et très différent d’une ligue classique.
12. Limites finales
Une probabilité n’est pas une certitude. Un badge Stable peut échouer. Un favori peut perdre. Un match peut basculer sur un rouge, un penalty, une blessure ou une erreur individuelle. C’est précisément pour cela que le modèle doit parler en distributions, pas en promesses.
Le bon objectif n’est pas d’avoir raison sur chaque match. Le bon objectif est d’être mieux calibré, plus lucide sur les zones de risque, capable de détecter ses propres dérives et suffisamment transparent pour que l’utilisateur comprenne ce qu’il lit.
Conclusion : une photographie scientifique, pas un point final
Cette série représente une photographie du moteur Foresportia à l’instant t. Elle montre un système déjà utile, avec des résultats encourageants, mais aussi des limites visibles et des pistes d’amélioration concrètes.
Conclusion de la série
Foresportia n’est pas conçu comme une promesse de certitude, mais comme un système de modélisation probabiliste, de mesure du signal, de validation empirique et d’amélioration continue.
Si cette série doit laisser une idée, c’est celle-ci : la valeur d’une IA de prédiction sportive ne réside pas dans son assurance, mais dans sa capacité à mesurer son incertitude et à s’améliorer honnêtement face aux résultats.
FAQ rapide
Les résultats présentés sont-ils définitifs ?
Non. Ils représentent un état du modèle à un instant donné. Le moteur évolue avec les données, les ligues couvertes, les calibrations et les cycles d’amélioration.
Une baisse de drift signifie-t-elle que le modèle est mauvais ?
Non. Elle indique une phase où les performances changent. Cela peut venir d’une ouverture à de nouvelles ligues, d’une saisonnalité particulière ou d’un réglage à améliorer.
Pourquoi publier les limites ?
Parce qu’une probabilité sérieuse doit être vérifiable et falsifiable. Masquer les limites rendrait le modèle moins crédible, pas plus fort.
Explorer Foresportia après la série
Retrouvez l’état du moteur, les matchs du jour, les résultats passés, l’API et les pages événementielles.
Voir l’état du programme IA