Cadre
Cet article ouvre une série de six notes techniques sur Foresportia. L’objectif n’est pas de présenter une promesse de résultat, mais de décrire comment un match de football peut être modélisé comme un problème probabiliste incertain, puis évalué sur des données historiques.
En bref
Foresportia ne cherche pas à “deviner” le futur. Le modèle estime une distribution de probabilités sur les issues possibles d’un match, puis mesure si cette distribution contient un signal exploitable. Sur le snapshot étudié de 14 623 matchs terminés, l’accuracy globale 1X2 est d’environ 54,0 %, mais les matchs classés Stable + Correct atteignent 78,5 % d’accuracy observée sur 21,9 % du volume.
Pourquoi cette série technique ?
Beaucoup de contenus de prédiction football réduisent un match à une réponse fermée : une équipe favorite, un score probable, un pourcentage affiché. Cette présentation est lisible, mais elle masque souvent le point central : un match de football est un événement probabiliste, bruité et fortement contextualisé.
Foresportia adopte une lecture différente. Le modèle ne cherche pas à transformer le football en système déterministe. Il cherche à estimer une distribution de probabilités, à mesurer la lisibilité de cette distribution, puis à vérifier sur les matchs terminés si cette lecture est cohérente avec les fréquences observées.
Cette première note pose donc le socle de toute la série. Elle ne détaille pas encore chaque module, mais elle explique le problème mathématique, la nature des données historiques, les premières métriques empiriques et la raison pour laquelle une probabilité doit toujours être accompagnée d’une mesure d’incertitude.
Cette note dans la série Foresportia Technical Notes
Cette page est le point d’entrée de la série. Elle introduit le problème global : passer d’un match réel à une distribution probabiliste exploitable. Les notes suivantes détaillent ensuite chaque brique du système.
1. Le football : un problème difficile à trois issues
En football, le résultat final d’un match peut être représenté par une variable aléatoire à trois classes :
Cette écriture paraît simple, mais elle change déjà la nature du problème. Le football n’est pas une classification binaire “gagne / perd”. Le match nul est une issue structurelle, fréquente, qui absorbe une partie importante de la masse de probabilité. Il ne suffit donc pas de mesurer quelle équipe est “meilleure” : il faut aussi estimer la probabilité que cette supériorité ne se traduise pas par une victoire.
- Faible nombre de buts : un seul événement peut changer totalement l’issue finale.
- Variance élevée : penalty, carton rouge, erreur individuelle ou but tardif peuvent dominer le signal statistique.
- Match nul structurel : une équipe peut être favorite sans que la probabilité de victoire dépasse fortement les alternatives.
- Contexte mouvant : forme récente, calendrier, fatigue, classement, enjeu, rotations et dynamique de saison.
- Hétérogénéité des ligues : les compétitions n’ont pas toutes le même rythme, la même fréquence de nuls ou la même stabilité.
Le problème mathématique n’est donc pas “qui va gagner ?”, mais plutôt :
Cette notation signifie : quelle est la probabilité de chaque issue Y, sachant l’information disponible avant le match
X ? Dans Foresportia, X peut contenir des signaux d’équipes, des signaux de ligue, des informations de forme,
des éléments de classement, des estimations ELO, des priors de buts, des données historiques et des variables contextuelles.
Le point important est le conditionnement. Le modèle ne cherche pas une vérité absolue sur le match ; il cherche une distribution
conditionnelle à l’information disponible. Si X est pauvre, bruité ou incomplet, la probabilité doit rester prudente.
Si plusieurs signaux convergent, la distribution peut devenir plus concentrée.
2. Une base empirique de 14 623 matchs terminés
Cette note s’appuie sur un snapshot historique de 14 623 matchs terminés suivis par Foresportia. Chaque ligne ne représente pas seulement un résultat final : elle relie une prédiction pré-match à un résultat observé. C’est cette structure qui permet de vérifier le modèle.
Pour chaque match, l’historique contient notamment les probabilités 1X2 publiées avant match, le score final, l’issue observée, la probabilité maximale, l’entropie, la marge de décision, la ligue, le badge de stabilité et, lorsque disponible, des signaux dérivés sur les buts ou le contexte.
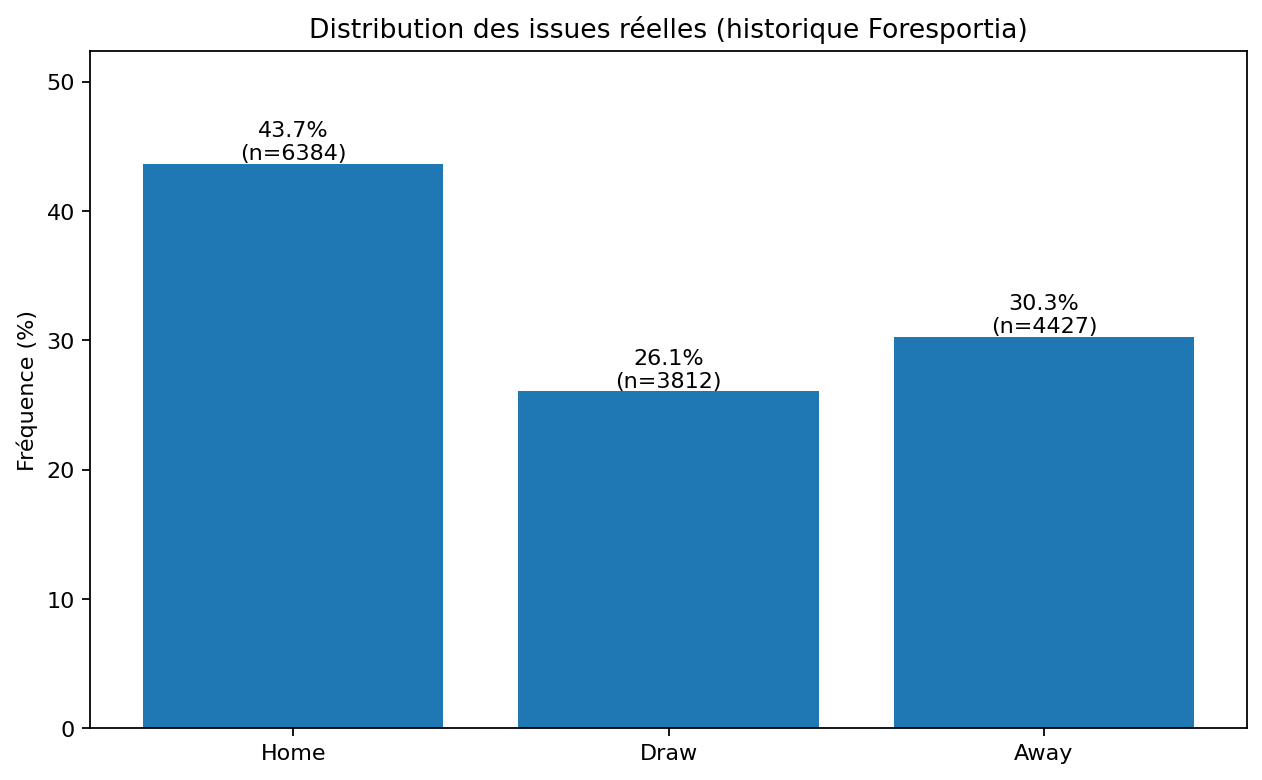
| Issue réelle | Matchs | Fréquence |
|---|---|---|
| Victoire domicile | 6 384 | 43,7 % |
| Match nul | 3 812 | 26,1 % |
| Victoire extérieure | 4 427 | 30,3 % |
La victoire domicile est l’issue la plus fréquente, mais elle ne représente que 43,7 % des matchs. Cela signifie qu’un modèle qui prédirait systématiquement le domicile échouerait encore plus d’une fois sur deux. Le match nul, à 26,1 %, est trop fréquent pour être traité comme une anomalie. Il doit être modélisé comme une issue à part entière.
Cette base sert donc à deux choses : mesurer la performance globale, mais aussi analyser où le modèle est bon, où il est fragile, et dans quels segments les probabilités deviennent réellement informatives.
3. Prédire une distribution, pas une certitude
Foresportia estime une distribution de probabilité :
Cette contrainte de somme à 1 est essentielle. Elle signifie que le modèle répartit une masse de probabilité entre plusieurs scénarios concurrents. Augmenter la probabilité d’une issue implique nécessairement de réduire la masse disponible pour les autres.
La prédiction principale est l’issue dont la probabilité est maximale :
L’opérateur argmax transforme une distribution en un choix unique. C’est utile pour calculer une accuracy,
mais cela détruit une partie de l’information. Un top pick à 38 % et un top pick à 72 % sont tous les deux des prédictions
au sens classification, mais ils ne portent pas le même niveau de confiance.
Une distribution (0.52, 0.25, 0.23) indique un favori plus lisible qu’une distribution
(0.38, 0.31, 0.31). Dans les deux cas, il existe une issue la plus probable, mais dans le second cas
les alternatives restent très proches. C’est précisément ce que les notes suivantes formaliseront avec la marge,
l’entropie et les badges.
Une probabilité n’est donc pas une promesse. Une probabilité de 60 % échoue encore environ 4 fois sur 10. Le modèle doit être jugé sur des groupes de matchs comparables, pas sur un match isolé.
4. Baselines simples : pourquoi le modèle doit faire mieux qu’une règle naïve
Avant de parler d’IA, il faut comparer le modèle à des règles simples. Une baseline n’est pas un concurrent sophistiqué : c’est un garde-fou méthodologique. Elle répond à une question simple : le modèle apporte-t-il plus qu’une heuristique évidente ?
| Méthode | Couverture | Accuracy |
|---|---|---|
| Toujours domicile | 14 623 matchs | 43,7 % |
| Favori au classement | 14 457 matchs | 47,4 % |
| Favori ELO simple | 3 729 matchs | 42,8 % |
| Foresportia 1X2 | 14 623 matchs | 54,0 % |
Dépasser la baseline “toujours domicile” est important, car cette règle exploite déjà une asymétrie réelle du football : les équipes à domicile gagnent plus souvent. Le gain de Foresportia signifie que le modèle ne se contente pas de reproduire l’avantage domicile ; il utilise des signaux supplémentaires pour déplacer la probabilité vers le nul ou l’extérieur lorsque les données le justifient.
Le vrai enjeu n’est cependant pas seulement l’accuracy globale. Une accuracy de 54,0 % mélange des matchs très lisibles, des matchs équilibrés et des matchs instables. La suite de l’article montre pourquoi il faut analyser la distribution elle-même.
5. Une architecture hybride : statistiques, probabilités et machine learning
Foresportia n’est pas uniquement un modèle de Poisson. Ce n’est pas non plus une boîte noire de machine learning. L’approche est hybride : des blocs statistiques structurent le problème, puis des couches de calibration et d’ajustement apprennent à rendre les probabilités plus cohérentes avec l’historique.
Dans cette écriture, fθ représente la fonction qui transforme les variables pré-match en probabilités.
Les paramètres θ ne doivent pas être compris comme une seule formule magique : ils peuvent regrouper des pondérations,
des calibrations, des seuils, des paramètres par ligue et des ajustements appris à partir de l’historique.
- Données d’équipes : attaque, défense, buts marqués, buts encaissés, forme récente.
- Données de ligue : rythme moyen, fréquence des nuls, priors Over/BTTS, niveau de dispersion.
- Contexte : domicile/extérieur, classement, progression de saison, fiabilité ELO.
- Historique : performances passées, calibration par ligue, erreurs observées, stabilité des segments.
Un modèle uniquement basé sur les buts attendus risque d’être trop mécanique. Un modèle uniquement machine learning risque d’être peu interprétable et sensible au bruit. L’hybridation permet de garder une structure probabiliste lisible tout en utilisant les données historiques pour corriger les biais, ajuster les niveaux de confiance et calibrer les sorties.
Point important
L’IA n’est pas utilisée comme argument magique. Dans Foresportia, elle sert à combiner les signaux, détecter les zones de mauvaise calibration, ajuster les probabilités et construire des niveaux de confiance. La Technical Note II détaille précisément cette couche machine learning.
6. Des forces d’équipe aux buts attendus
Une étape importante consiste à estimer les buts attendus pour chaque équipe :
Un lambda n’est pas une prédiction de score. λH=1.6 ne signifie pas que l’équipe à domicile
va marquer exactement 1,6 but. Cela signifie que, dans un modèle de comptage, l’intensité offensive attendue se situe autour
de ce niveau. Cette intensité sert ensuite à répartir la probabilité entre les scores possibles.
Ces valeurs ne sont pas de simples moyennes historiques. Elles doivent tenir compte de la force offensive de l’équipe, de la solidité défensive adverse, du domicile/extérieur, du rythme de la ligue, de la forme récente, du classement, de l’ELO et de garde-fous lorsque les données disponibles sont faibles.
Cette formule simplifiée montre que les buts attendus sont une interaction entre deux équipes, pas une propriété isolée. Une attaque forte ne produit pas le même lambda contre une défense faible ou une défense dominante. Le contexte modifie ensuite l’intensité : domicile, rythme de compétition, forme et fiabilité de l’historique.
7. De la grille de scores aux probabilités 1X2
À partir des lambdas, le modèle construit une distribution sur les scores possibles :
Cette expression désigne la probabilité du score exact i-j. En pratique, le modèle ne s’intéresse pas à un seul score :
il construit une grille de scores et répartit une masse de probabilité sur cette grille.
Dans le cas le plus simple, on peut utiliser une loi de Poisson :
Cette loi est utile parce qu’elle modélise des événements de comptage rares : 0, 1, 2, 3 buts, etc. Elle n’est toutefois qu’un point de départ. Dans le football réel, les buts peuvent être corrélés, certaines ligues sont plus ouvertes, certains petits scores sont surreprésentés, et les données peuvent être trop rares pour certaines équipes.
Le moteur Foresportia peut donc intégrer de la surdispersion, des corrections sur les petits scores, des effets de ligue, des garde-fous sur les données faibles et des mécanismes de calibration.
Le 1X2 est une agrégation de scénarios de score. Tous les scores où le domicile marque plus que l’extérieur contribuent à P(H).
Tous les scores égaux contribuent à P(D). Tous les scores où l’extérieur marque plus contribuent à P(A).
Cela relie directement le modèle des buts à la distribution 1X2.
8. Calibration : transformer une probabilité brute en probabilité exploitable
Une probabilité brute peut être mal calibrée. Un modèle peut annoncer beaucoup de matchs à 70 % alors que ces événements ne se réalisent que 60 % du temps. Dans ce cas, il est trop confiant. À l’inverse, un modèle peut être trop prudent et sous-estimer ses propres signaux.
Ici, zc représente un score interne associé à l’issue c, et T
une température de calibration. Lorsque T augmente, la distribution devient plus prudente :
les probabilités extrêmes sont ramenées vers le centre. Lorsque T diminue, la distribution devient plus tranchée.
La calibration est le pont entre un score de modèle et une probabilité interprétable. Un classement correct des matchs ne suffit pas : si le modèle affiche 70 %, cette zone doit tendre vers environ 70 % de réussite observée sur un volume suffisant. C’est l’un des endroits où l’IA et le machine learning apportent une valeur concrète : apprendre où le modèle doit être corrigé.
9. Quand la probabilité maximale devient informative
La probabilité maximale est définie par :
Si le modèle est utile, les matchs avec une probabilité maximale plus élevée doivent réussir plus souvent. C’est exactement ce qui apparaît dans l’historique Foresportia.
p_max mesure l’intensité du signal dominant. Il ne dit pas encore tout sur la qualité du match,
mais il donne une première information : le modèle voit-il une issue clairement plus probable que les autres ?
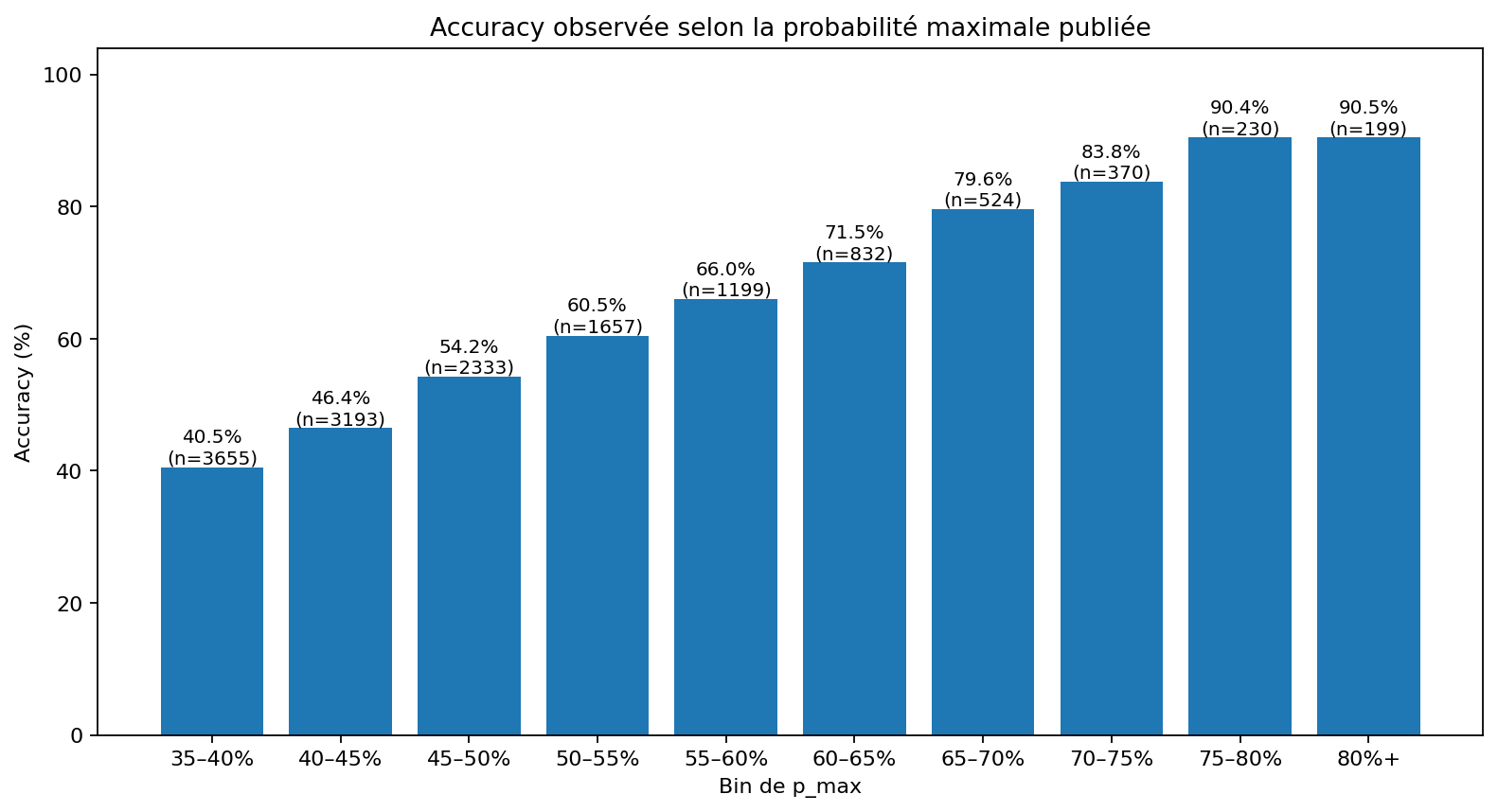
| pmax | Matchs | Accuracy observée |
|---|---|---|
| 35–40 % | 3 657 | 40,5 % |
| 40–45 % | 3 193 | 46,4 % |
| 45–50 % | 2 333 | 54,2 % |
| 50–55 % | 1 657 | 60,5 % |
| 55–60 % | 1 199 | 66,0 % |
| 60–65 % | 832 | 71,5 % |
| 65–70 % | 524 | 79,6 % |
| 70–75 % | 370 | 83,8 % |
| 75–80 % | 230 | 90,4 % |
| 80 % + | 199 | 90,5 % |
Le passage de la zone 35–40 % à la zone 70–75 % fait passer l’accuracy observée de 40,5 % à 83,8 %.
Cela confirme que p_max n’est pas décoratif : il contient une information réelle sur la concentration
du signal. Mais ce n’est pas suffisant : une probabilité élevée peut encore être fragilisée par une entropie élevée,
une mauvaise calibration ou un contexte sportif instable.
10. Entropie : mesurer la lisibilité de la distribution
La probabilité maximale ne décrit pas toute la distribution. Pour mesurer son degré de dispersion, on utilise l’entropie :
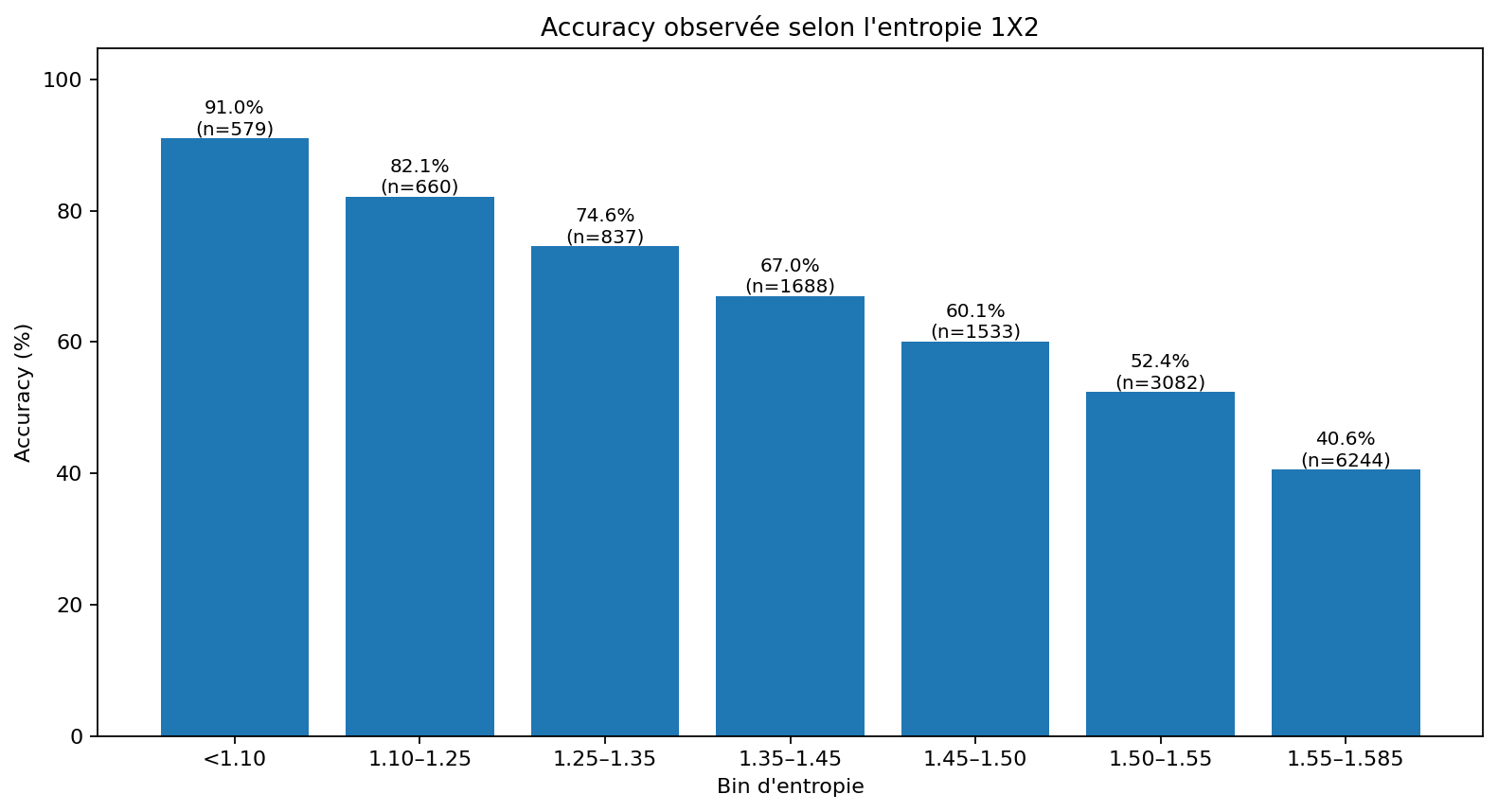
| Entropie 1X2 | Matchs | Accuracy observée |
|---|---|---|
| < 1.10 | 579 | 91,0 % |
| 1.10–1.25 | 660 | 82,1 % |
| 1.25–1.35 | 837 | 74,6 % |
| 1.35–1.45 | 1 688 | 67,0 % |
| 1.45–1.50 | 1 533 | 60,1 % |
| 1.50–1.55 | 3 082 | 52,4 % |
| 1.55–1.585 | 6 244 | 40,6 % |
L’écart entre les distributions très peu entropiques (< 1.10) et les distributions très entropiques (1.55–1.585) est massif : 91,0 % contre 40,6 %. Cela montre que la qualité d’un pronostic dépend de la forme complète de la distribution, pas seulement de l’issue arrivée en tête.
L’entropie agit donc comme une mesure de lisibilité. Elle ne remplace pas la probabilité, mais elle dit si la probabilité dominante est isolée ou noyée dans une distribution presque uniforme.
11. Des probabilités aux badges de stabilité
Foresportia ne publie pas seulement une probabilité brute. Le modèle associe aussi un niveau de stabilité :
Une formulation simplifiée du score de confiance peut s’écrire :
| Segment | Matchs | Couverture | Accuracy |
|---|---|---|---|
| Stable | 1 371 | 9,4 % | 85,3 % |
| Correct | 1 838 | 12,6 % | 73,5 % |
| Stable + Correct | 3 209 | 21,9 % | 78,5 % |
| Risk | 11 414 | 78,1 % | 47,1 % |
| Tous matchs | 14 623 | 100 % | 54,0 % |
L’accuracy globale de 54,0 % masque deux régimes statistiques. Le segment Stable + Correct couvre seulement 21,9 % des matchs, mais atteint 78,5 % d’accuracy observée. Le segment Risk couvre la majorité du volume, mais tombe à 47,1 %. La segmentation ne sert donc pas à embellir le modèle : elle sépare les zones où le signal est exploitable des zones où l’incertitude reste dominante.
12. Première lecture de calibration : probabilité prédite vs fréquence observée
Un modèle probabiliste doit être évalué autrement qu’un simple classifieur. Il faut comparer les probabilités annoncées aux fréquences réellement observées.
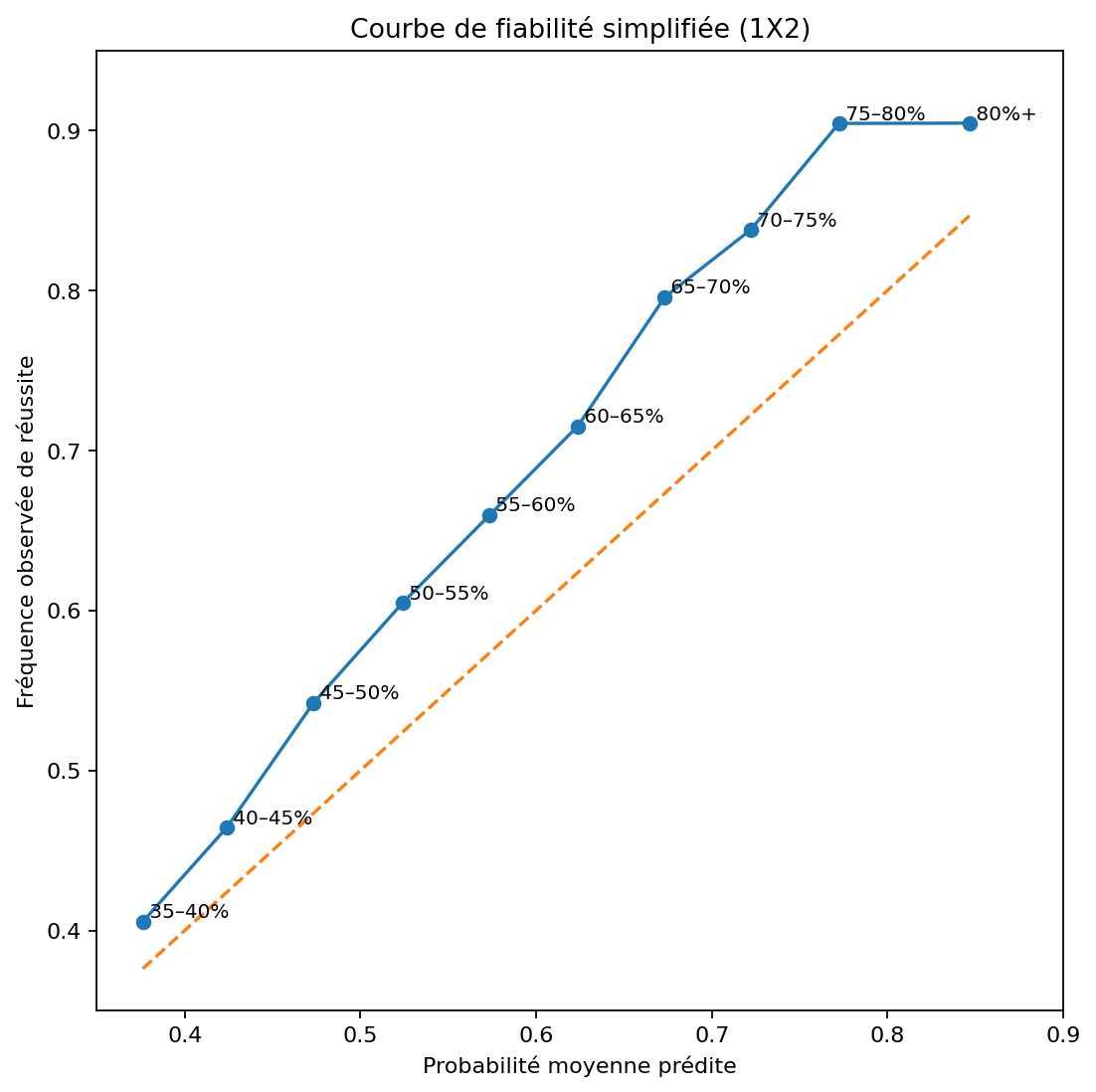
Cette figure est volontairement présentée comme une première lecture. Elle ne remplace pas une validation complète, mais elle illustre le principe : une probabilité utile doit pouvoir être confrontée aux fréquences observées.
Si une zone de probabilité moyenne à 60 % réussit seulement 48 % du temps, le modèle est trop confiant dans cette zone. Si elle réussit 72 % du temps, il est trop prudent. La Technical Note VI reviendra sur cette question avec Brier score, log loss, Expected Calibration Error et drift temporel.
13. Toutes les ligues ne se comportent pas de la même façon
Les performances ne sont pas homogènes d’une ligue à l’autre. Cela justifie l’utilisation de paramètres par ligue, de priors spécifiques, de garde-fous et de mécanismes de calibration. Une compétition plus ouverte, plus instable ou moins bien couverte historiquement peut dégrader la fiabilité du signal.
| Ligue | Matchs | Accuracy globale |
|---|---|---|
| Champions League | 502 | 63,9 % |
| Norvège | 303 | 61,4 % |
| Ligue 1 | 601 | 59,4 % |
| Portugal | 600 | 58,5 % |
| Serie A | 739 | 58,3 % |
| Bundesliga | 602 | 58,1 % |
| Japon | 483 | 48,9 % |
| Corée | 302 | 47,7 % |
| Suisse | 217 | 46,1 % |
Un modèle global peut masquer des réalités locales. Certaines ligues dépassent nettement la moyenne globale, tandis que d’autres restent plus difficiles. Ce point est important pour un produit réel : il faut surveiller les performances par compétition, ajuster les calibrations et éviter d’appliquer le même niveau de confiance partout.
14. Ouverture vers les marchés de buts
Foresportia ne se limite pas au 1X2. Le modèle produit aussi des lectures sur les buts : scores probables, BTTS, Over/Under, clean sheet, double chance et draw no bet.
| Marché | Matchs | Accuracy seuil 50 % | Probabilité moyenne | Fréquence observée |
|---|---|---|---|---|
| BTTS | 3 714 | 58,1 % | 55,8 % | 56,4 % |
| Over 2.5 | 3 714 | 59,1 % | 55,1 % | 54,6 % |
| Under 2.5 | 3 714 | 59,1 % | 45,0 % | 45,4 % |
Ces chiffres suggèrent une calibration globale raisonnable, mais une discrimination plus limitée que sur les meilleurs segments 1X2. La cinquième note expliquera plus précisément les lambdas de buts, les scores probables, le BTTS et les marchés Over/Under.
15. Limites : ce qu’un modèle ne peut pas savoir
Même un modèle bien calibré reste limité. Certaines informations sont absentes, retardées ou impossibles à connaître parfaitement : composition réelle, blessure de dernière minute, météo locale, fatigue individuelle, choix tactique, penalty, carton rouge, décision arbitrale ou événement rare.
Une bonne probabilité peut donc échouer sur un match isolé. L’objectif n’est pas de faire monter artificiellement les probabilités, mais de rendre chaque pourcentage plus honnête, plus interprétable et plus vérifiable.
Conclusion : la valeur est dans la mesure du signal
Foresportia modélise un match de football comme un problème probabiliste incertain :
Les résultats historiques montrent que l’accuracy augmente avec la probabilité maximale, diminue lorsque l’entropie augmente, et que les badges Stable/Correct isolent des zones de meilleure performance observée.
Thèse centrale
La valeur d’un modèle de prédiction football ne réside pas seulement dans son taux de réussite global, mais dans sa capacité à mesurer l’incertitude et à identifier les zones où le signal est réellement exploitable.
Continuer la série Technical Notes
Cette première note définit le cadre général : une prédiction football doit être lue comme une distribution probabiliste. Les articles suivants approfondissent chaque brique du système.
FAQ rapide
Foresportia prédit-il le futur ?
Non. Foresportia estime des probabilités à partir des données disponibles. Une probabilité élevée signifie une fréquence attendue plus forte, pas une certitude.
Pourquoi parler d’IA si le modèle utilise aussi des statistiques ?
Parce que l’IA intervient dans la combinaison, l’ajustement et la calibration des signaux. Le système est hybride : statistiques explicables, modèle probabiliste, calibration et apprentissage sur historique.
Pourquoi l’accuracy globale ne suffit-elle pas ?
Parce qu’elle mélange des matchs très lisibles et des matchs très incertains. Les segments Stable, Correct et Risk mesurent où le signal est réellement exploitable.
Les marchés de buts sont-ils calculés comme le 1X2 ?
Non. Ils utilisent une logique dédiée autour des lambdas de buts, des grilles de scores et de calibrations spécifiques. Le détail sera présenté dans la Technical Note V.
Passer de la théorie aux matchs du jour
Cette note décrit les fondations du modèle. Pour consulter les sorties concrètes du moteur Foresportia, explorez les pages de résultats, les top pronostics IA et l’historique des performances.
Voir les meilleurs signaux IA du jour