Idée centrale
Dans Foresportia, l’IA n’est pas une baguette magique. Elle sert à transformer les données brutes en signaux exploitables, à classer les situations par niveau de risque, à corriger les biais et à combiner plusieurs lectures de confiance.
Le problème : “IA” ne veut rien dire sans architecture
Dire qu’un modèle utilise de l’IA n’apprend presque rien. Un modèle peut être une simple règle, une régression, un modèle de buts, un classifieur, une couche de calibration ou un assemblage de tout cela. Pour comprendre Foresportia, il faut donc répondre à une question plus précise : où intervient l’apprentissage, et que corrige-t-il réellement ?
La Technical Note I a posé le cadre probabiliste : un match est une distribution 1X2 conditionnée par l’information pré-match. Cette deuxième note explique comment l’IA intervient entre les données brutes et les probabilités finales.
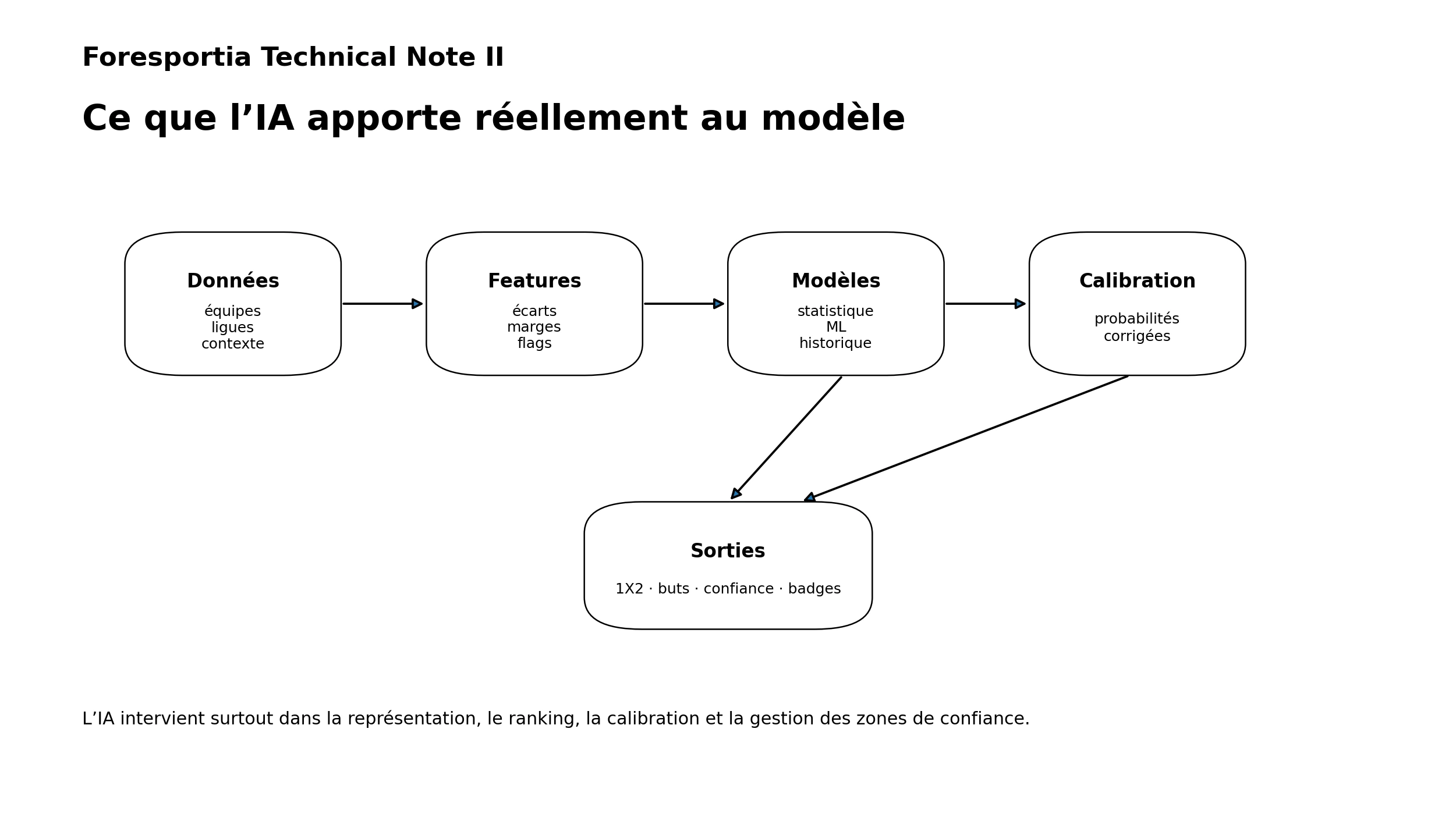
1. Une architecture hybride, pas une boîte noire
Foresportia combine plusieurs couches : données pré-match, feature engineering, modèles candidats, calibration, puis sorties produit. L’IA intervient surtout dans les couches intermédiaires : représentation, ranking, correction et fusion.
Cette équation ne dit pas que tout est appris par un seul modèle. Elle dit que les probabilités finales dépendent
d’un ensemble de familles de signaux. Les paramètres θ peuvent regrouper des poids statistiques,
des paramètres de calibration, des seuils par ligue, des corrections contextuelles et des modèles ML entraînés sur l’historique.
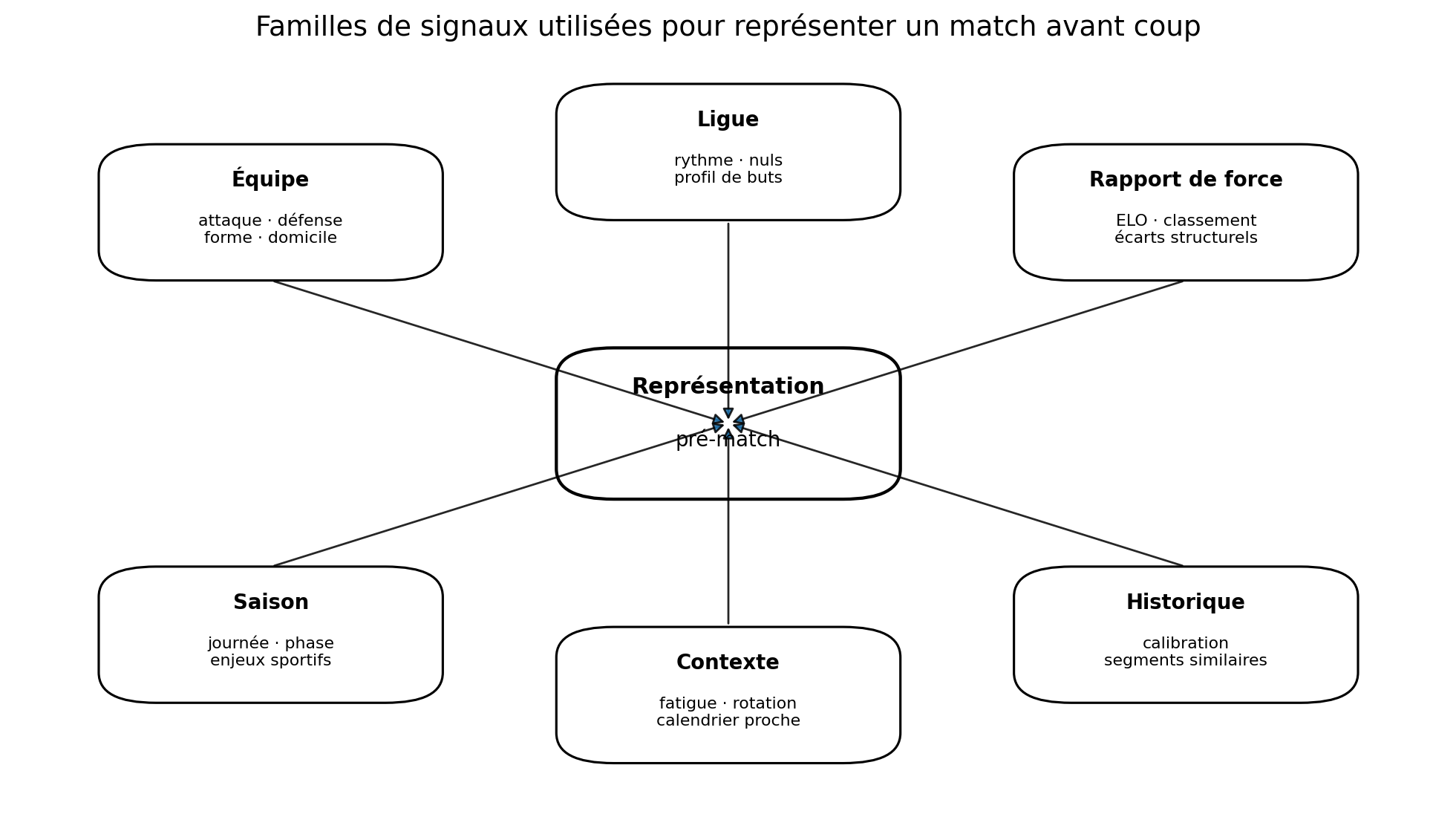
2. Ce que l’on donne réellement à l’IA
Le machine learning ne travaille pas sur “un match” abstrait. Il travaille sur une représentation structurée du match avant coup. Cette représentation doit résumer les forces des équipes, leur contexte, leur environnement de championnat et les signaux historiques comparables.
Cette notation signifie que le modèle n’utilise pas une seule variable magique. Il combine plusieurs familles de signaux, chacune décrivant une dimension différente du match.
- Équipe : forme récente, dynamique offensive et défensive, comportement domicile/extérieur.
- Ligue : rythme moyen, fréquence des nuls, profil de buts, niveau de stabilité historique.
- Rapport de force : niveau structurel des équipes, écart de classement, écart ELO, cohérence entre ces signaux.
- Saison : journée, phase de saison, début de saison bruité, fin de saison à enjeux asymétriques.
- Contexte : fatigue, enchaînement des matchs, rotation probable, proximité d’un match européen, déplacement.
- Historique : comportement observé de configurations similaires et calibration empirique du modèle.
Deux matchs peuvent avoir une probabilité 1X2 proche, mais ne pas porter le même niveau de risque. Un favori reposé, cohérent avec le classement et dans une ligue stable n’est pas équivalent à un favori en période de rotation, en fin de saison, avec un calendrier dense et un signal historique plus fragile.
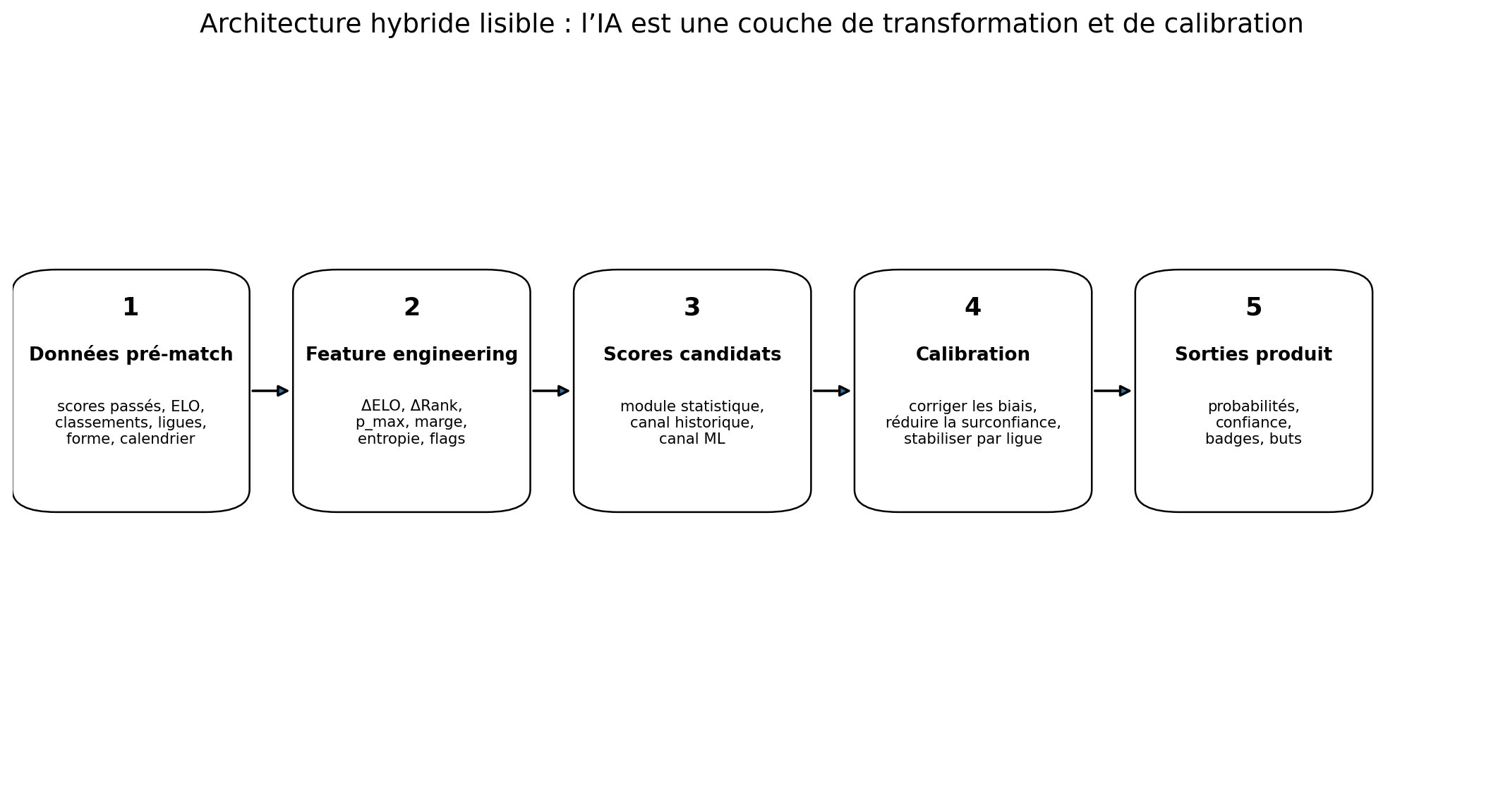
3. Feature engineering : la partie décisive avant le modèle
Une variable brute est rarement suffisante. L’IA devient utile quand on transforme ces données en signaux comparables.
Ces écarts sont plus informatifs que les valeurs isolées. Une équipe classée 5e n’a pas le même sens selon la ligue, la journée, l’écart de points, le niveau ELO et la qualité de l’adversaire.
Le même écart ELO peut être très fiable dans une ligue stable et beaucoup moins dans une ligue volatile. Un classement peut être informatif en fin de saison, mais encore très bruité après quatre journées. Le feature engineering sert à donner au modèle des variables qui portent déjà cette nuance.
4. Interactions non linéaires : le vrai intérêt du machine learning
Les signaux ne s’additionnent pas simplement. L’effet d’un bon ELO dépend du domicile, du contexte de ligue, de la forme récente, du classement et parfois de la période de saison.
Cette écriture simplifiée montre une interaction : l’effet de l’ELO peut changer selon que l’équipe joue à domicile ou non.
Un modèle ML peut généraliser cette idée à de nombreuses interactions : p_max × entropie,
classement × saison, ELO × fiabilité, favorite trap × fin de saison.
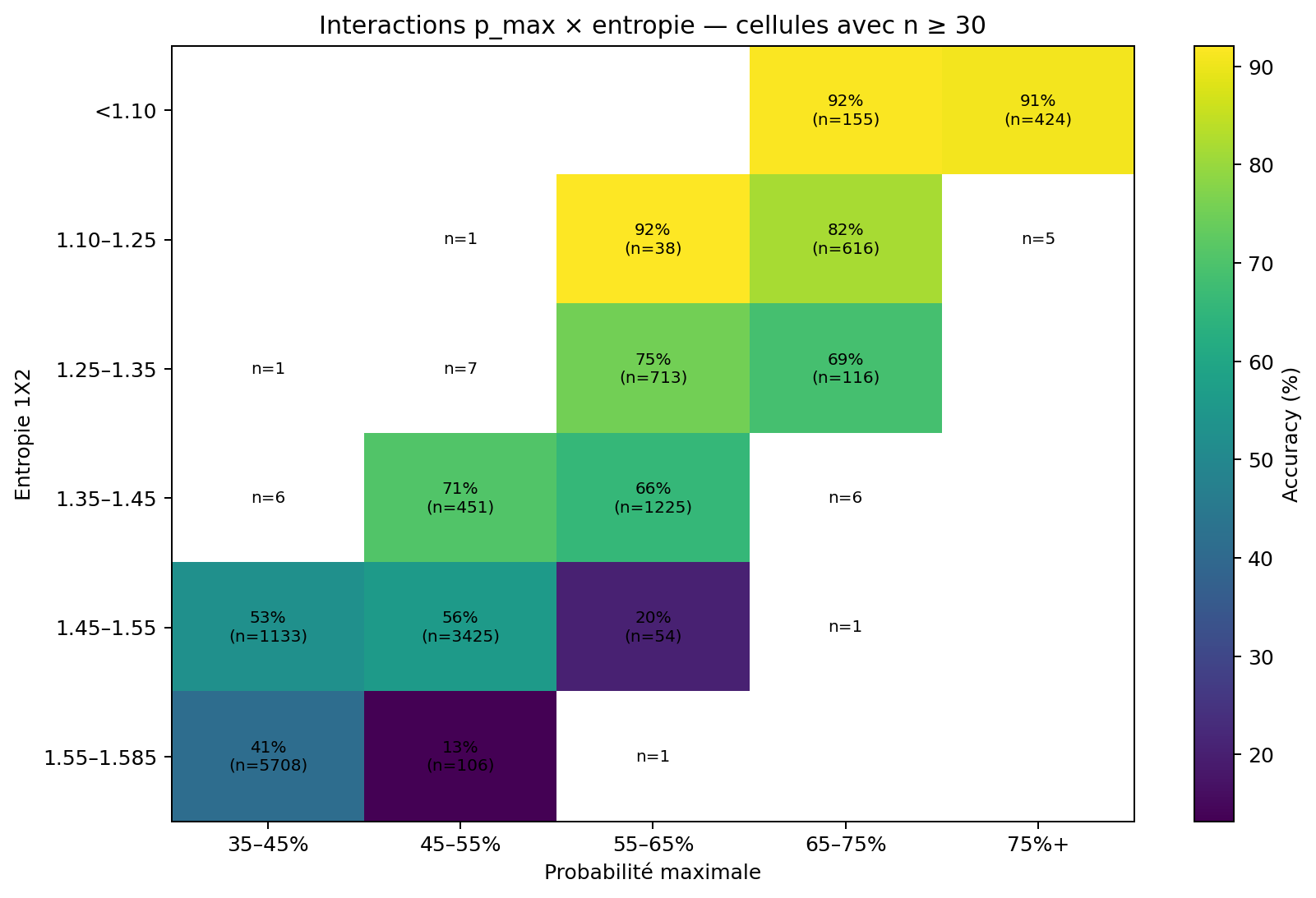
p_max et entropie doivent être lus ensemble. Les cellules à très faible volume ne sont pas affichées comme des 0 %.
5. Trois lectures complémentaires : mémoire empirique, ML et score stabilisé
Foresportia ne s’appuie pas sur une seule lecture de confiance. Le système combine plusieurs angles : une mémoire statistique issue de l’historique, une lecture machine learning capable de détecter des interactions, puis une couche finale plus prudente destinée à produire une information exploitable.
| Lecture | Rôle | Limite |
|---|---|---|
| Mémoire empirique | Compare le match à des configurations historiquement similaires. | Peut manquer de finesse si les situations comparables sont rares. |
| Lecture machine learning | Apprend des interactions entre signaux : forme, ELO, contexte, entropie, saison. | Peut bien classer les matchs tout en restant imparfaitement calibrée. |
| Score stabilisé | Combine les signaux pour produire une lecture plus robuste et moins surconfiante. | Doit rester vérifié sur les résultats terminés. |
Cette formule est volontairement générique. Elle indique que le score final n’est pas une simple sortie brute d’un modèle : il combine une mémoire empirique, une lecture ML, des indicateurs de distribution et des signaux de contexte.
6. Ce que le ML apporte vraiment : mieux classer les zones de risque
Le premier intérêt d’un score ML n’est pas toujours d’être une probabilité parfaitement calibrée. Il peut d’abord servir à trier les matchs : si on garde uniquement les matchs avec les scores les plus élevés, l’accuracy observée doit augmenter.
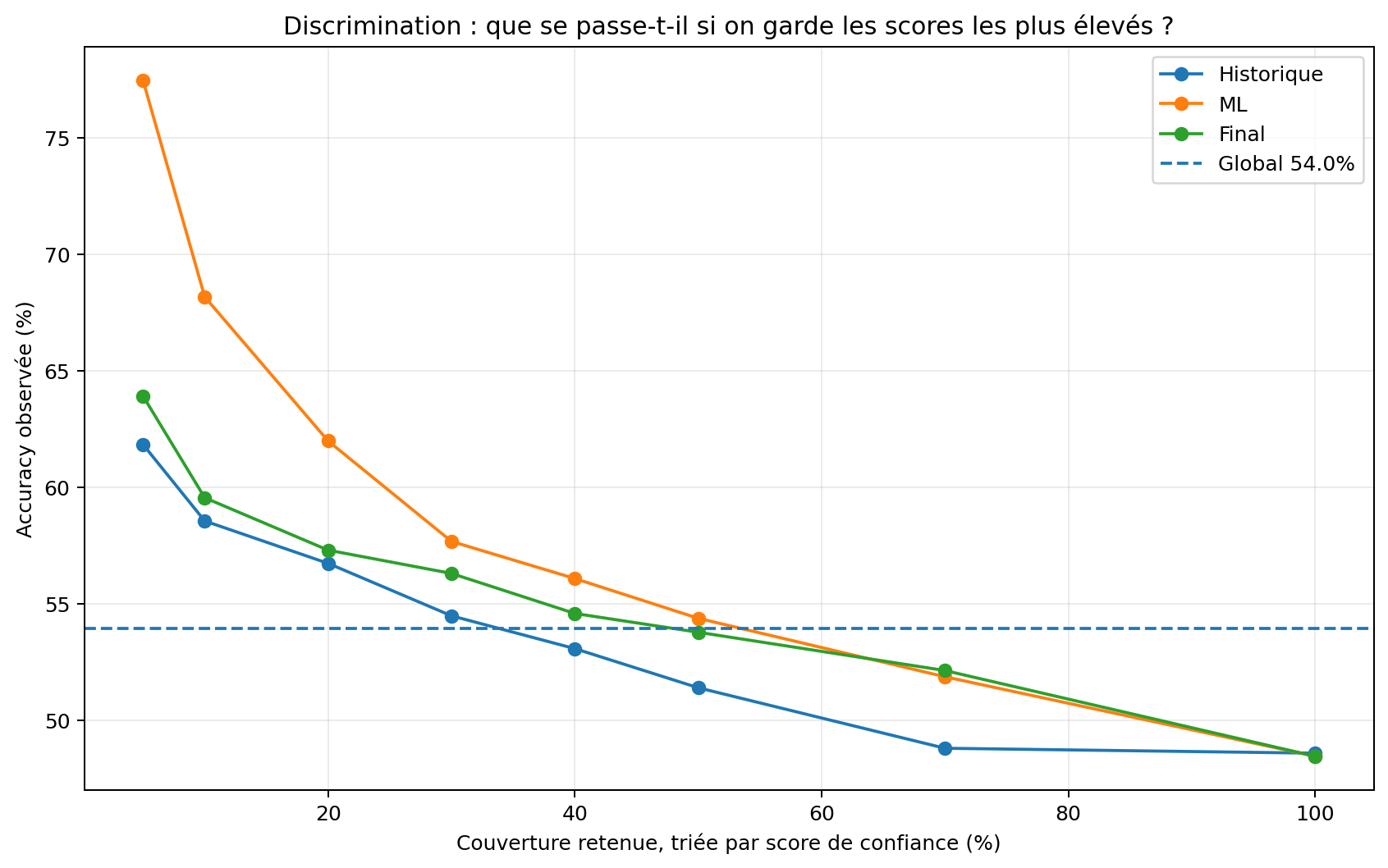
Lorsque les matchs sont triés par score de confiance, les zones les mieux classées présentent une meilleure réussite observée. C’est le rôle principal du machine learning ici : aider à distinguer les situations réellement lisibles des situations où la probabilité brute reste fragile. En revanche, un bon classement du risque ne suffit pas à garantir une calibration parfaite.
7. Calibration : pourquoi un score IA ne doit pas être lu trop vite comme une probabilité
La calibration vérifie si un score annoncé correspond réellement à une fréquence observée. Par exemple, si un groupe de matchs est présenté autour de 70 %, il devrait réussir autour de 70 % du temps sur un volume suffisant. C’est une exigence forte, et elle est différente de la simple capacité à classer les matchs.
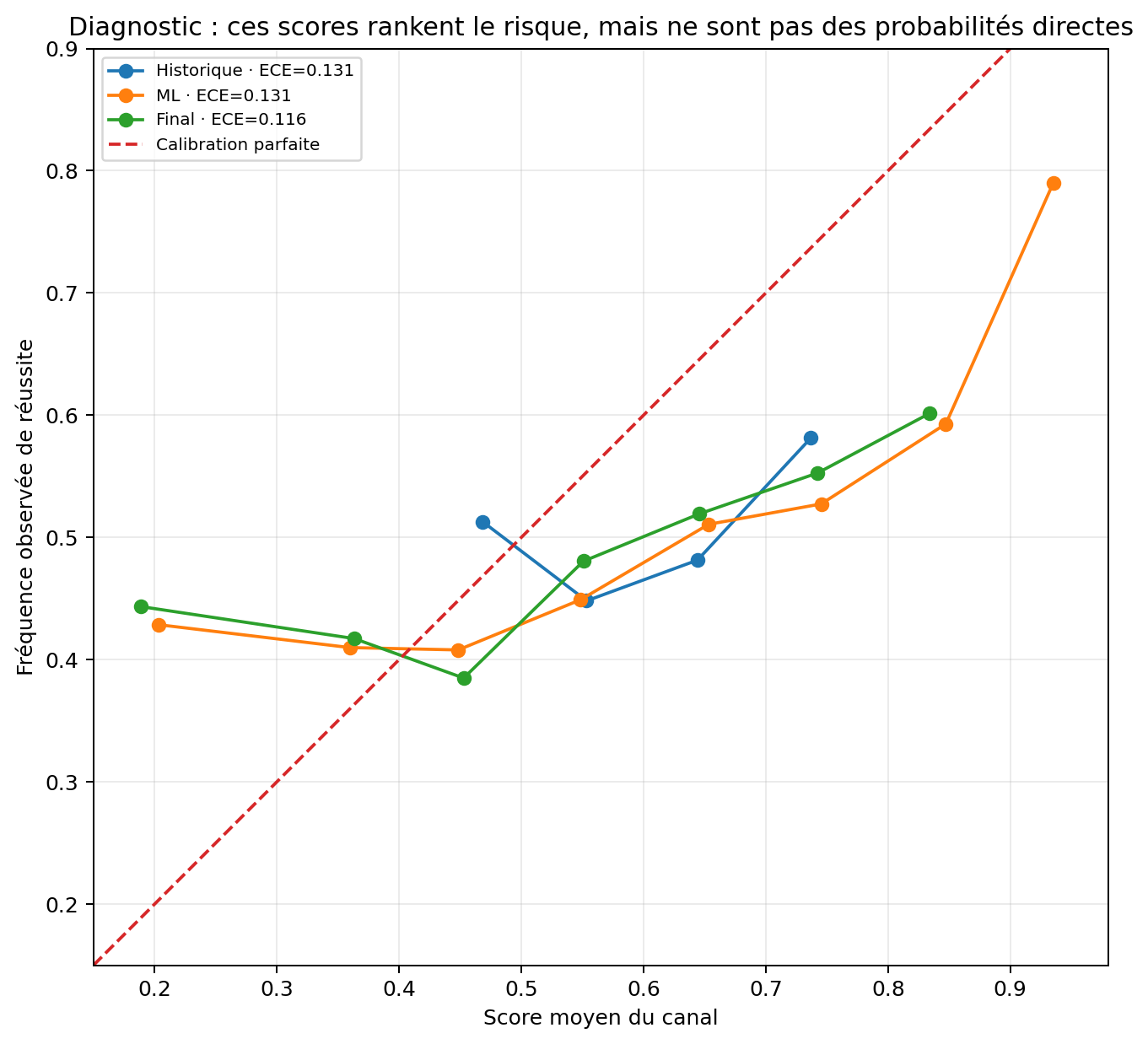
Cette courbe n’est pas là pour embellir artificiellement le modèle. Elle montre une distinction essentielle : une lecture machine learning peut détecter les matchs les plus intéressants, tout en nécessitant une calibration avant d’être interprétée comme une probabilité directe. C’est précisément pour cela que Foresportia sépare probabilité 1X2, score de confiance et badge de stabilité.
Cette séparation évite une erreur fréquente : confondre un score de ranking avec une probabilité. Le score aide à ordonner les matchs par stabilité attendue ; la probabilité, elle, doit rester vérifiable face aux fréquences observées.
8. Les signaux contextuels qui encadrent l’IA
Une partie importante de la robustesse ne vient pas seulement d’un modèle statistique ou d’un classifieur. Elle vient aussi de signaux contextuels qui indiquent quand une probabilité brute doit être lue avec prudence.
| Famille de signal | Rôle dans le modèle | Pourquoi c’est utile |
|---|---|---|
| Classement au moment du match | Compare la probabilité au rapport de force visible dans la compétition. | Détecte les situations où le modèle voit un favori qui contredit fortement le classement. |
| Domicile / extérieur | Sépare les performances selon le lieu du match. | Une équipe dominante à domicile peut être beaucoup moins fiable à l’extérieur. |
| Journée et phase de saison | Replace le match dans le déroulé de la saison. | Le début de saison est bruité ; la fin de saison introduit des enjeux asymétriques. |
| Fatigue et congestion | Repère les calendriers rapprochés. | Un favori peut devenir plus fragile si la récupération est courte. |
| Rotation probable | Signale les contextes où l’équipe type peut être modifiée. | La force moyenne de l’équipe ne reflète pas toujours le onze réellement aligné. |
| Proximité européenne | Identifie les matchs proches d’une échéance européenne. | Le championnat peut être influencé par la priorité donnée à une autre compétition. |
| Enjeux sportifs | Intègre maintien, titre, qualification ou absence d’objectif fort. | Deux équipes de niveau comparable peuvent ne pas avoir la même intensité attendue. |
| Favorite trap | Détecte les favoris statistiques rendus fragiles par le contexte. | Évite de transformer un favori théorique en signal trop confiant. |
Ces signaux ne prédisent pas le résultat à eux seuls. Ils servent surtout à contrôler la surconfiance : lorsqu’un match coche plusieurs facteurs de prudence, la lecture finale doit être plus conservatrice.
9. Ce que l’IA ne peut pas faire
L’IA ne connaît pas toujours une blessure non déclarée, une consigne tactique, une composition inattendue ou l’intensité réelle d’une équipe déjà qualifiée. Elle ne peut pas prédire un carton rouge ou un penalty. Elle peut seulement apprendre quelles situations historiques ressemblent à des zones de signal fort ou faible.
C’est pourquoi Foresportia doit combiner plusieurs couches : probabilités, confiance, badges, contexte et validation empirique. L’objectif n’est pas de vendre une certitude, mais d’éviter d’afficher une certitude là où le modèle ne dispose que d’un signal fragile.
Conclusion : l’IA comme couche de représentation et de contrôle du risque
L’IA apporte de la valeur lorsqu’elle améliore la représentation du match, détecte des interactions non linéaires, classe mieux les zones de risque et aide à corriger la surconfiance. Elle n’annule pas l’incertitude du football.
Conclusion-clé
Dans Foresportia, le machine learning ne remplace pas le modèle probabiliste : il l’aide à mieux représenter, trier, calibrer et expliquer les zones où le signal est réellement exploitable.
La Technical Note III détaille maintenant comment cette logique devient une lecture produit : probabilité maximale, marge, entropie et badges Stable, Correct et Risk.
FAQ rapide
Foresportia est-il seulement un modèle Poisson ?
Non. Les lambdas de buts sont une brique importante, mais le système ajoute des features, de l’historique, des canaux ML, de la calibration et des flags contextuels.
Le canal ML est-il meilleur que l’historique ?
Il peut être meilleur pour classer les matchs les plus lisibles, mais il peut aussi être surconfiant. C’est pourquoi il doit être combiné et calibré.
Pourquoi afficher un diagnostic de calibration imparfait ?
Parce que c’est exactement ce qui rend la démarche crédible : montrer qu’un score de confiance n’est pas automatiquement une probabilité et qu’il doit être surveillé.
Voir les signaux Foresportia en pratique
Les pages Foresportia permettent de consulter les probabilités, badges et résultats passés du modèle.
Voir les signaux IA du jour