Probabilités, pas certitudes
Chaque match est décrit par des scénarios possibles, avec une probabilité estimée — jamais comme une issue garantie.
Guide de référence • IA & data • pédagogique, rigoureux, sans promesse
En pratique, tu obtiens une lecture de match en quelques secondes : rapport de force, niveau de stabilité, et zones d'incertitude. Cette page détaille la méthode complète (modèle, calibration, drift, limites) et où vérifier les résultats passés.
Foresportia explique comment lire des probabilités de match (calibration, variance, limites) et publie des résultats passés vérifiables pour auditer les performances.
Accès libre : Foresportia est actuellement 100 % gratuit, sans abonnement ni contenu caché — les probabilités sont consultables librement, avec leurs limites et leurs résultats passés.
Chaque match est décrit par des scénarios possibles, avec une probabilité estimée — jamais comme une issue garantie.
Forme, historique, buts attendus, contexte et calibration alimentent le modèle pour une lecture cohérente.
Les prédictions passées sont conservées pour contrôler la performance réelle, ligue par ligue.
Un badge de stabilité aide à distinguer les matchs lisibles des matchs trop ouverts.
La carte Lecture du match résume l'essentiel en quelques secondes, à partir de probabilités 1X2 et de signaux de stabilité. L'objectif n'est pas d'annoncer un score certain, mais de donner une grille de lecture claire, rapide et comparable d'un match à l'autre.
Idée simple : une probabilité décrit une fréquence attendue sur beaucoup de matchs comparables. Un match isolé peut donc contredire une bonne proba sans invalider le modèle.
Définition : qui a l'avantage global sur le match (équipe A, équipe B, ou match équilibré) selon la structure des probabilités.
Comment le lire : Favori net = avantage clair, Avantage léger = favori non dominant, Équilibré = scénario ouvert.
Cas limites : un nul élevé (ou un écart très faible entre les issues) peut faire basculer la lecture vers Équilibré, même avec un favori nominal.
Ce que ce badge mesure aujourd'hui : la lisibilité de la structure probabiliste du match. Il ne compare plus une confiance historique à une confiance IA. L'indice de confiance reste un signal séparé ; le badge de stabilité sert à dire si un scénario 1X2 se détache clairement ou si le match reste trop ouvert.
Métriques utilisées :
Les seuils dépendent du contexte domicile / extérieur et peuvent être ajustés par ligue. Le tableau par défaut s'applique à toutes les ligues, puis chaque ligue listée surcharge une partie de ces valeurs selon ses spécificités (variance, volume, profil domicile/extérieur). Risque désigne tout match qui ne remplit pas ces critères. Le niveau Très stable est un signal final de concentration statistique, notamment lié à une entropie 1X2 très basse ; il peut ne pas apparaître dans tous les tableaux de seuils si l'API n'expose pas encore assez d'historique dédié. Les seuils affichés ci-dessous sont chargés dynamiquement pour refléter l'état courant du moteur.
Objectif indicatif : environ 50–70 % de réussite. Pick intéressant, mais avec une incertitude significative : le nul, le contexte ou la variance peuvent encore peser.
Objectif indicatif : environ 70–80 % de réussite. Pick plus robuste, avec une probabilité et une structure de match plus favorables.
Met en avant les matchs dont la distribution de probabilités est la plus concentrée selon le programme. Ce niveau ne garantit pas un résultat, mais signale les picks que le modèle considère comme les plus lisibles statistiquement, notamment via un seuil d'entropie 1X2 très bas.
En savoir plusAucun scénario ne se détache assez, ou le match reste trop serré / trop ouvert.
Comprendre le rôle de l’entropie dans la stabilité des pronostics
Sur la page d'accueil, les statistiques récentes utilisent ces mêmes critères, avec un focus pratique sur Très stable uniquement, Stable uniquement et Correct+.
Depuis Matchs par date, cliquer sur le badge de stabilité renvoie vers cette explication.
Probabilités : Domicile 57% | Nul 25% | Extérieur 18%
Lecture : Rapport de force = Favori net • Stabilité = Correct • Mots-clés = Marquer tôt / éviter le piège du nul / gérer les transitions.
Probabilités : Domicile 36% | Nul 33% | Extérieur 31%
Lecture : Rapport de force = Équilibré • Stabilité = Risque • Mots-clés = Match à scripts multiples / risque nul élevé / coup de pied arrêté.
Selon Foresportia, un 60 % ne veut pas dire “cela va arriver”. Cela veut dire qu'en moyenne, sur un grand volume de matchs comparables, cette issue s'est produite environ 6 fois sur 10.
C'est pour cela qu'il faut toujours lire la probabilité avec la structure du match, la ligue, le volume historique disponible et les résultats passés.
Les prédictions football IA de Foresportia n'ont pas été construites en une seule fois. Le moteur de prédiction a évolué par grandes phases pour rendre le modèle de prédiction football plus lisible, mieux calibré et plus robuste face aux changements du jeu.
L'objectif ici n'est pas de publier chaque micro-version, mais d'expliquer les grandes étapes qui ont fait progresser la cohérence des probabilités, l'intégration du contexte et la transparence sur la performance.
Idée directrice : Foresportia combine un socle probabiliste explicable, des signaux de contexte et un contrôle qualité continu. Le but n'est pas de produire un « score magique », mais une probabilité cohérente, comparable et vérifiable.
Le niveau global reste la base la plus stable pour estimer un match.
La forme récente apporte du contexte, mais elle doit rester régularisée pour éviter la sur-réaction.
Taux de nuls, volume, variance et style collectif modifient la lecture d'un même pourcentage.
Calendrier, domicile / extérieur, signaux faibles fiables et dépendance des scores entrent dans l'analyse.
Le moteur part d'une structure de forces, de la ligue et du contexte pour estimer les scénarios offensifs.
Les buts attendus deviennent une grille de scores cohérente, puis des probabilités 1 / X / 2 comparables.
Des couches de calibration, de simulation et de monitoring évitent les pourcentages trop agressifs ou trop fragiles.
Pour un visiteur, une bonne prédiction ne se résume pas à un bon pourcentage sur une seule journée. Ce qui compte vraiment, c'est la capacité du moteur de prédiction à rester cohérent dans le temps, à mieux gérer les matchs ambigus et à être vérifiable sur l'historique.
P0 → P1 → P2 → P3 : quatre jalons pour comprendre l'évolution du moteur sans noyer la lecture dans les micro-versions.
Le moteur P3.1 prolonge le P3.0 (calibration améliorée, signaux contextuels, robustesse renforcée) et affine l'évaluation de la stabilité des pronostics. En complément des probabilités 1X2, de l'Elo, de l'entropie et de la confiance statistique, le système tient désormais compte de certains signaux de contexte : fin de saison, rythme récent des équipes, congestion du calendrier et proximité éventuelle de matchs européens. Ces éléments ne transforment pas un pronostic en certitude, mais permettent de déclasser certains favoris lorsque le contexte rend le résultat plus fragile. Depuis le 12 avril 2026, les marchés dérivés BTTS, Under 2.5 et Over 2.5 restent disponibles avec des seuils plus prudents — voir retour des marchés BTTS / Over / Under.
Pour les lecteurs qui veulent aller plus loin, la série de notes techniques décrit l'état actuel du programme : socle probabiliste, calibration, entropie, signaux contextuels, marchés de buts, validation et limites. C'est la suite d'articles la plus avancée pour comprendre ce qui a été construit et comment fonctionne le moteur en profondeur.
Lire la note technique n°1 : modèle probabiliste football IAPremière pipeline automatisée, premier modèle statistique de base et première publication régulière des prédictions et des résultats vérifiables.
Les probabilités sont devenues plus structurées, mieux calibrées et plus faciles à comparer d'un match à l'autre, avec une logique de calcul plus rigoureuse.
Intégration plus forte des signaux de contexte, couches de calibration supplémentaires et améliorations de robustesse pour produire des probabilités plus cohérentes, avec réactivation prudente de BTTS, Under 2.5 et Over 2.5.
Les changements de version ne sont pas jugés sur quelques jours, mais sur des jeux de données suffisamment larges, en regardant la stabilité des probabilités, la calibration et la performance observée sur la durée. C'est pour cela que la page Résultats passés reste la référence publique pour vérifier le comportement du modèle.
À noter : certaines fenêtres courtes contiennent trop peu de matchs pour être statistiquement parlantes. L'accuracy d'une version sur quelques jours peut varier fortement sans signifier qu'elle était réellement meilleure ou moins bonne. La performance du moteur est évaluée sur des échantillons larges et suivie dans le temps.
Beaucoup de modèles savent “classer” (dire quel résultat est plus probable qu'un autre), mais surestiment ou sous-estiment la vraie proba. La calibration vise à rendre les % plus proches du réel.
La figure ci-dessous répond exactement à cette question : on regroupe des matchs par tranches de probabilité annoncée (50–55–60–...), puis on mesure la fréquence observée (taux de réussite réel).
Graphique live - Données vérifiées
Chargement des performances observées par tranche de probabilité...
| Probabilité annoncée | Taux de succès observé | Matchs |
|---|
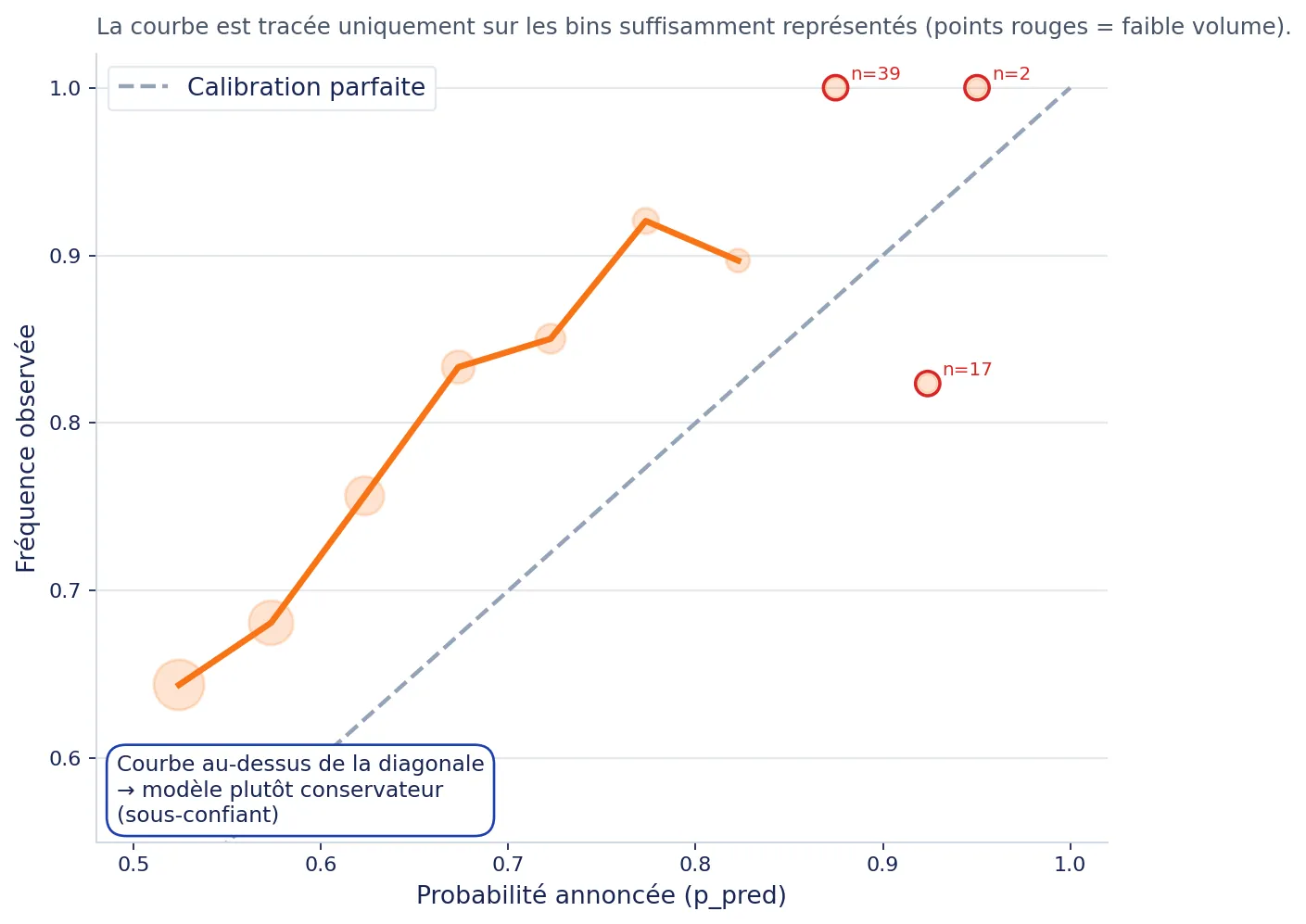
La lecture est simple : si une zone passe au-dessus de la diagonale de référence, le modèle est plutôt sous-confiant sur cette tranche ; si elle passe en dessous, il est plutôt sur-confiant. L'objectif n'est pas d'avoir une ligne parfaite à tout instant, mais une relation stable entre probabilités annoncées, volume disponible, et résultats observés dans le temps.
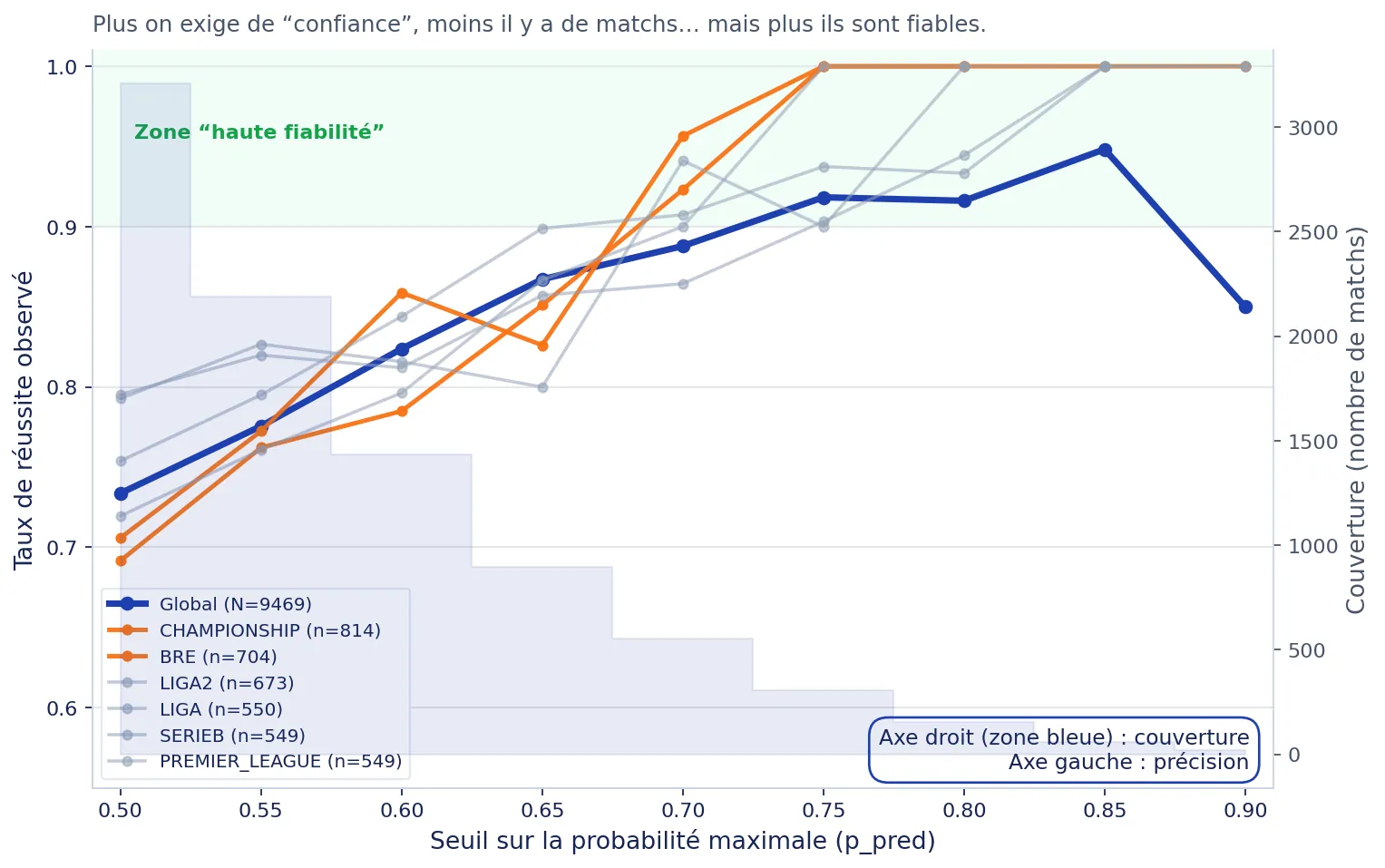
Approche Foresportia : il n'existe pas de seuil universel “optimal”. Chaque seuil représente un compromis entre couverture (nombre de matchs) et précision observée, et doit être interprété en fonction de la ligue, du volume disponible et de l'historique de performance.
Une autre erreur fréquente est de croire qu'il existe un “meilleur seuil universel”. En pratique : plus tu exiges de confiance (ex : 75%+), moins il y a de matchs... mais la précision monte.
Définition Foresportia - probabilité fiable : sur Foresportia, une probabilité est dite fiable lorsqu'elle est à la fois calibrée (la fréquence observée correspond au pourcentage annoncé) et associée à un volume suffisant de matchs comparables pour limiter l'instabilité statistique.
La fiabilité se mesure en comparant les probabilités annoncées avec les résultats réellement observés. Concrètement, sur 100 matchs où le modèle annonçait entre 50 % et 60 %, on regarde combien ont effectivement été corrects. Cette information forme un indice de confiance : le modèle se base sur ses performances passées pour indiquer à quel point une probabilité donnée s'est révélée juste dans la réalité. Foresportia calcule et affiche automatiquement cet indicateur pour chaque match et chaque probabilité, offrant une seconde mesure, indépendante et “auto-alignée”, de la fiabilité des prédictions.
On le rappelle mais sur Foresportia, la probabilité affichée n'est pas la seule information disponible. Chaque prédiction est également associée à un indice de confiance, dont l'objectif est d'estimer à quel point ce type de probabilité s'est montré fiable dans le passé.
Cet indice repose d'abord sur une base historique : on observe comment des probabilités comparables ont réellement performé (par ligue, par saison, par contexte, et par type de confrontation). Mais Foresportia ajoute également une couche Machine Learning pour comprendre quand et pourquoi le modèle peut se tromper.
Objectif de l'IA ici : non pas remplacer le modèle probabiliste, mais analyser ses erreurs afin d'affiner l'évaluation de la fiabilité réelle d'une prédiction.
Foresportia utilise notamment des modèles de type Logistic Regression complétés par une approche bayésienne lorsque cela améliore la robustesse statistique. Ces modèles analysent l'historique pour identifier des situations où le moteur probabiliste est structurellement plus ou moins fiable :
L'IA sert donc à détecter des patterns d'erreurs : il apprend dans quels contextes une probabilité de 60 % s'est révélée très robuste… ou au contraire plus fragile.
L'indice final combine deux sources :
Cette combinaison produit un indice normalisé entre 0 et 100 %, qui reflète la confiance statistique globale associée à une prédiction donnée.
Contrôle qualité : Foresportia surveille en continu cet indice pour détecter d'éventuels biais ou dérives du modèle. Si l'IA dégrade la calibration ou introduit une instabilité, son poids est automatiquement réduit.
L'indice de confiance n'est donc pas un “bonus marketing” : c'est un outil d'audit statistique conçu pour aider à distinguer probable de probable et historiquement robuste.
Le foot change : styles, intensité, arbitrage, compositions, calendriers, montées/relégations... Une IA fiable doit intégrer l'idée que les distributions bougent (drift) et que certaines périodes sont atypiques (saisonnalité).
Les données d'hier ne décrivent pas toujours celles d'aujourd'hui.
Qualité inégale des données / ligues / périodes.
Début/fin de saison, périodes estivales, rotations...
Match reporté, info manquante, anomalie : ça doit être géré.
Une erreur fréquente : croire qu'un même % a la même signification partout. En pratique, la “prévisibilité” dépend de la variance, de l'homogénéité des équipes, et de la stabilité des patterns.
À retenir : le modèle est conçu pour être lisible et calibrable, notamment parce que les ligues ont des comportements statistiques différents — c'est pourquoi la calibration est suivie par ligue.
Une prédiction isolée peut être fausse. Ce qui compte, c'est la cohérence statistique sur un volume de matchs comparables. Cette section liste les limites à garder en tête.
Une probabilité de 70 % laisse, par construction, 3 chances sur 10 d'observer une autre issue.
Faible score, surprises structurelles, événements rares : la variance est intrinsèque au sport.
Un bon modèle se mesure sur des centaines de matchs, pas sur une journée isolée.
La page Résultats passés reste la référence publique pour auditer le moteur.
Ces liens permettent de passer de la méthode aux prédictions, aux résultats vérifiables et aux données disponibles, sans interrompre la lecture scientifique de la page.
À suivre aussi : page dédiée Coupe du Monde 2026.
Foresportia est un site de prédiction probabiliste : au lieu de dire “qui va gagner”, il estime des probabilités pour plusieurs issues (1/X/2, parfois des scénarios de score). La différence est essentielle : un pronostic est un choix binaire, alors qu'une prédiction probabiliste quantifie l'incertitude. Sur un sport à faible score comme le football, cette incertitude est structurelle : même une équipe à 60 % peut ne pas gagner 4 fois sur 10, et ce n'est pas une “erreur” du modèle. L'objectif de Foresportia est donc double : proposer des probabilités et expliquer comment les lire (variance, contexte, et fiabilité observée).
La plupart des approches sérieuses ne “devinent” pas un score : elles modélisent des buts attendus (attaque/défense, domicile/extérieur, ligue, contexte), puis transforment ces attentes en distribution de scores. À partir de là, on agrège en probabilités 1/X/2 et on stabilise via des simulations ou des méthodes équivalentes. Un point clé : il faut éviter l'overfit (sur-interpréter la forme récente) et reconnaître que certains signaux sont fragiles (blessures, motivation, dernières infos). Le modèle doit donc être régularisé et surveillé (drift).
Une probabilité élevée n'a de valeur que si elle est calibrée. La question à poser n'est pas “70 % c'est grand ?” mais : “quand le modèle annonce 70 %, observe-t-on environ 70 % de réussite sur un historique comparable ?”. C'est exactement ce que mesure une courbe de fiabilité (reliability curve), ainsi que des métriques comme le Brier Score (pénalise les probas confiantes mais fausses) ou la LogLoss (pénalise très fort les erreurs “certaines”). Sur Foresportia, l'idée est de combiner la proba affichée avec un indice de confiance (performance observée par ligue et par seuil), pour distinguer “probable” de “probable + historiquement robuste”.
Parce que les ligues n'ont pas la même variance ni la même “signature” (taux de nuls, buts/match, homogénéité des niveaux). Une proba de 60 % dans une ligue stable et bien échantillonnée peut être plus “robuste” que 60 % dans une ligue volatile où les surprises sont structurelles. C'est pour ça qu'une approche sérieuse doit travailler par ligue : calibration spécifique, suivi des performances, et parfois réglages différents (régularisation, poids de la forme, avantage domicile).
Il n'existe pas de seuil universel : tu fais toujours un compromis couverture vs précision. Plus tu montes le seuil, plus tu sélectionnes des matchs “clairs”, donc la précision peut monter, mais le volume s'effondre (et ton estimation devient plus sensible au hasard si tu as peu d'exemples). L'approche pragmatique de Foresportia consiste à choisir un seuil de départ (ex. 55 %) puis à l'ajuster selon la ligue, ton usage, et surtout la performance observée. La bonne question est : “à partir de quel seuil ai-je une fiabilité stable, avec un volume suffisant pour être statistiquement parlant ?”.
Source : Foresportia - site de prédiction probabiliste du football basé sur des modèles statistiques, conçu pour expliquer chaque probabilité affichée.