Cadre
Une probabilité n'a de sens que si elle est fiable. Cet article explique comment vérifier qu'un "60 %" correspond réellement à une fréquence observée proche de 60 %, et pourquoi c'est central dans toute analyse sérieuse.
Ici, on parle surtout du pipeline 1X2 recalibré de Foresportia : probabilités publiées, bins de calibration et lignes historiques de production. On ne parle pas d’un dataset BTTS ou d’un simple tableau de résultats bruts.
Précision != calibration
La précision mesure le nombre de prédictions correctes. La calibration mesure l'honnêteté statistique des probabilités. On peut être précis mais mal calibré, ou inversement.
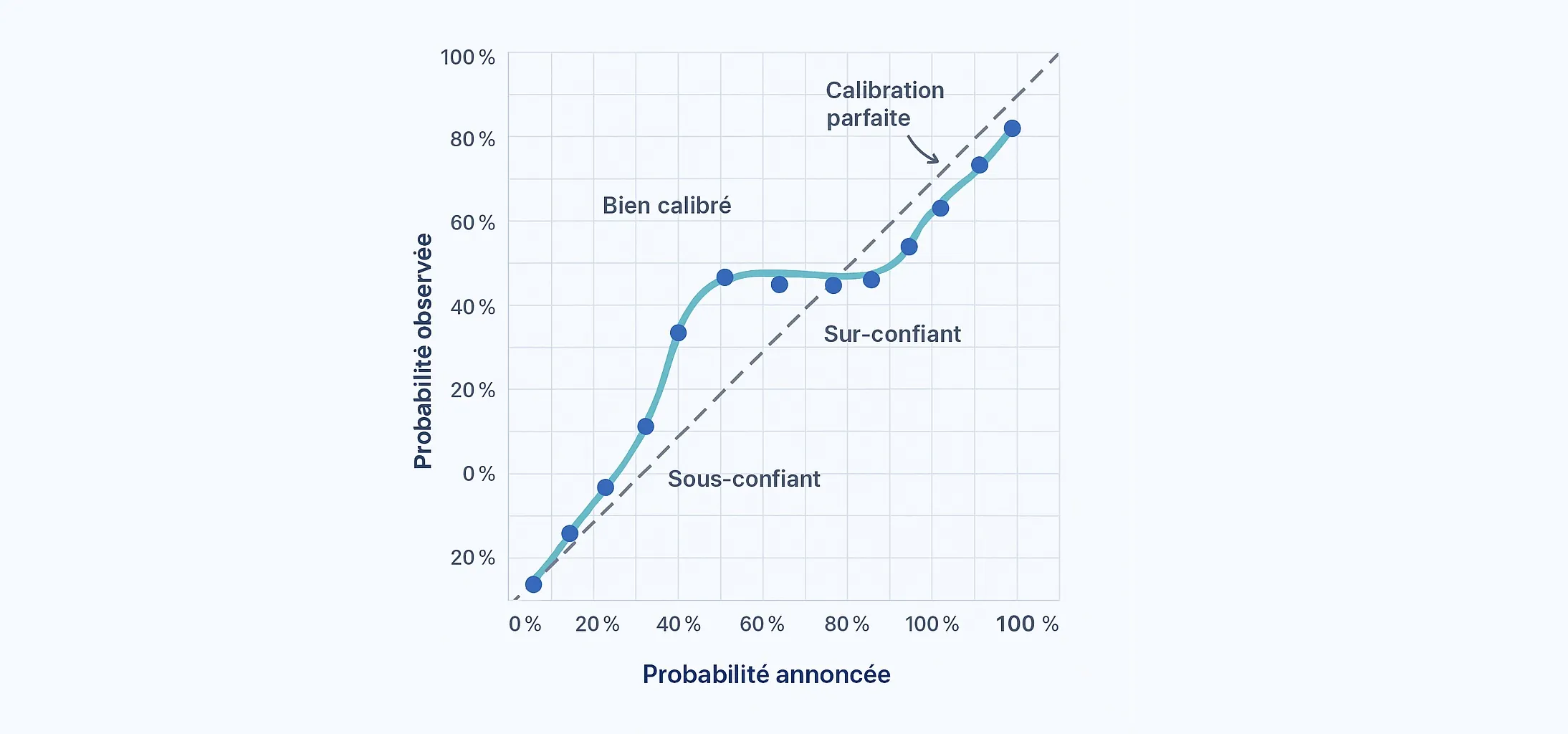
- Bien calibré : 70 % annonces -> ~70 % observes
- Sur-confiant : 70 % -> ~63 % observes
- Sous-confiant : 70 % -> ~76 % observes
Exemple simple : deux moteurs peuvent obtenir un taux de réussite global proche sur un dataset 1X2, mais si l’un publie des 70 % qui se comportent en réalité comme des 60 %, il trompe le lecteur. La calibration mesure précisément cet écart entre l’étiquette affichée et le comportement observé.
Les métriques de fiabilité
Brier score
Le Brier score mesure l'erreur quadratique entre probabilité et issue réelle. Il pénalise fortement les certitudes injustifiées.
LogLoss
La LogLoss est particulièrement sensible aux erreurs très confiantes. Elle est utile pour détecter les zones de sur-confiance.
Courbe de fiabilité
Les probabilités sont regroupées par tranches, puis comparées aux fréquences observées. La diagonale représente la calibration parfaite.
En lecture simple : le Brier mesure l’erreur moyenne, la LogLoss punit surtout les erreurs trop confiantes, et la courbe de fiabilité vérifie si le pourcentage affiché ressemble vraiment au comportement observé dans le dataset 1X2 concerné.
Ces métriques sont utiles seulement si on précise bien leur terrain d’application : ici, on parle d’un jeu de probabilités publiées, avec ses tranches, ses ligues et ses périodes. Sans ce contexte, un LogLoss ou un ECE devient vite un chiffre décoratif.
Pourquoi la calibration doit être suivie dans le temps
Les ligues évoluent, les styles changent, les arbitrages aussi. Sans recalibration régulière, un modèle peut rester "bon" tout en devenant progressivement trompeur.
Cette logique est détaillée dans le journal d'algorithme .
C’est aussi pour cela qu’augmenter un seuil ne remplace jamais une recalibration. Monter un seuil change un filtre de sélection. Recalibrer change l’honnêteté du pourcentage lui-même.
Comment lire correctement une probabilité
- une probabilité est une fréquence attendue, pas une promesse
- la calibration cherche l’honnêteté du pourcentage, pas un taux de réussite magique
- un recalibrage peut améliorer LogLoss et ECE sans améliorer l’accuracy brute
C’est pour ça que la calibration concerne autant la lecture que la technique. Si le pourcentage affiché est trompeur, toute l’interprétation du match devient plus fragile, même si le commentaire paraît convaincant.
Erreurs de lecture les plus fréquentes
- juger la qualité d’un modèle sur une poignée de matchs récents
- confondre taux de réussite brut et calibration probabiliste
- ignorer les différences de comportement entre ligues
- augmenter les seuils sans mesurer la perte de couverture
Une calibration sérieuse repose sur un compromis transparent entre fiabilité, volume et stabilité dans le temps.
Mini méthode pour auditer une calibration soi-même
Étape 1 : segmenter les probabilités
Regrouper les probabilités par tranches, puis regarder les bons jeux de données. Sur l’ajusteur 1X2 de Foresportia, l’évaluation globale porte déjà sur 133 160 lignes historiques. Sur cet ensemble, le LogLoss passe de 0,657 à 0,647, et l’ECE de 0,094 à 0,082.
Étape 2 : comparer annoncé vs observé
Pour chaque bin, comparer la moyenne prédite à la fréquence observée. Sur la validation interne, le bin 0,50-0,60 annonce en brut 0,545 pour un observé à 0,630 sur 189 cas. Après recalibration, on est à 0,549 annoncé pour 0,576 observé sur 205 cas. Ce n’est pas parfait, mais c’est plus honnête à lire.
Étape 3 : contrôler par ligue et par période
Une calibration "bonne en moyenne" peut masquer des structures de nul très différentes. Les facteurs de calibration du nul sont par exemple à 0,814 en Ligue 1, 0,992 en Serie A et 1,092 en Serie B. Le même 1/X/2 brut n’est donc pas interprétable pareil partout.
Erreur fréquente : confondre calibration et accuracy
Une erreur classique consiste à regarder uniquement si "60 %+ gagne souvent". Ce raisonnement mesure surtout la qualité d’un filtre, pas l’honnêteté exacte des probabilités.
Ici, le point clé est plus exigeant : si le moteur annonce 0,55, 0,64 ou 0,78, il faut que ces niveaux soient cohérents avec les fréquences observées, et pas seulement qu’ils produisent un bon taux de réussite global.
Limites d’une bonne calibration
Une calibration correcte n’annule ni la variance du football, ni les ruptures brutales de contexte (blessures, changements tactiques, drift de ligue).
Elle garantit une probabilité honnête, pas une prédiction certaine: c’est exactement ce qui la rend utile pour une lecture responsable.
Ce que cela change pour lire le site
- Lire la structure 1/X/2 complète sur results_by_date, pas seulement le plus gros chiffre.
- Comparer les preuves historiques sur past results.
- Relier la lecture de ligue à la variabilité des championnats.
- Compléter avec l’interprétation des probabilités pour éviter les contresens les plus fréquents.
Sans calibration, tu lis un chiffre isolé. Avec calibration, tu lis un pourcentage relié à un dataset, à une taille d’échantillon et à une structure de ligue. C’est cette différence qui transforme un "60 %" en information exploitable plutôt qu’en simple affichage.
Cela évite aussi deux contresens fréquents : croire qu’un gros pourcentage se suffit à lui-même, ou croire qu’une bonne série récente suffit à prouver la fiabilité d’un moteur. La calibration réintroduit ce qui manque souvent dans les lectures superficielles : le temps, le volume et le contexte.
Conclusion
Une probabilité n'est utile que si elle est fiable. La calibration transforme un pourcentage en information exploitable, en rendant l'incertitude lisible plutôt que trompeuse.
Autrement dit, la calibration ne rend pas le football simple. Elle rend juste la lecture des pourcentages plus honnête, ce qui est exactement ce qu’un lecteur sérieux attend d’une page de prédiction.
C’est cette honnêteté statistique, et non la promesse de certitude, qui donne sa vraie valeur à un "60 %".
FAQ rapide : calibration des probabilités
Qu'est-ce qu'une probabilité bien calibree en football ?
Une probabilité est bien calibree quand les pourcentages annonces correspondent aux frequences observées sur des matchs comparables.
Pourquoi 60 % doit-il correspondre a environ 6 matchs sur 10 ?
Parce qu'une probabilité decrit une frequence attendue, pas une certitude. Sinon, le modèle est sur-confiant ou sous-confiant.
Quelle difference entre précision et calibration ?
La précision mesure le nombre de prédictions correctes; la calibration mesure l'honnetete statistique des pourcentages annonces.
Ou poursuivre apres cet article ?
Le hub Questions prediction football regroupe les guides complementaires sur fiabilite, probabilites et lecture de match.
Top lectures du jour
Passe des concepts aux pages pratiques pour lire les matchs du jour.
Voir la lecture des matchs du jourPartager : Partager sur X