
Pourquoi une mise à jour ?
Fin mars 2025, nous observions un phénomène double : plus de matchs ≥55 % tout en détectant une légère sur-confiance dans la bande 55–65 %. Pour rester « honnêtes » statistiquement, nous avons renforcé la calibration par ligue et ajouté une couche d’auto-configuration des paramètres (seuils, pondérations temporelles) pilotée par le drift monitoring.
Ce que nous avons changé (et pourquoi)
1) Calibration par ligue (isotonic / Platt)
Chaque championnat possède sa variance : nous ré-étalonons désormais les probabilités ligue par ligue, via isotonic regression (échantillons denses) ou Platt scaling (échantillons modestes).
2) Pondération temporelle (time-decay)
Les matchs récents pèsent davantage, ce qui améliore la réactivité du modèle face aux changements tactiques et aux séries.
3) Auto-config des seuils & régularisation
Le système ajuste automatiquement : seuils par ligue (micro-pas ±1–2 pts), force du time-decay et régularisation (moyennage ligue ↔ global quand les données récentes sont rares). Des garde-fous limitent l’amplitude et la fréquence des changements.
4) Drift monitoring & validation stricte
Chaque nuit, nous suivons Brier, LogLoss et ECE ; si une dérive dépasse un seuil de tolérance, la ligue est recalibrée. Toute validation se fait en split chronologique (no look-ahead).
Réussite globale @55 %
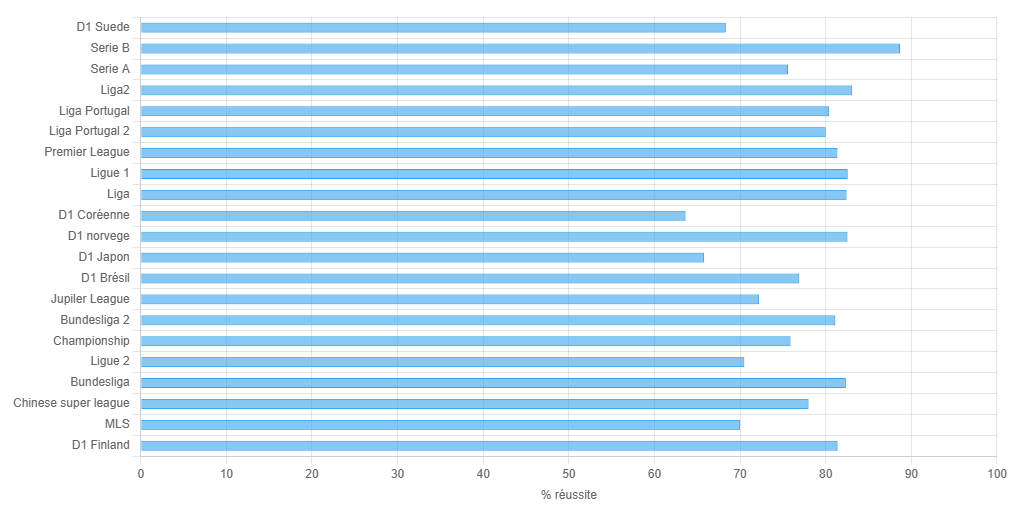
Le graphique ci-dessus correspond au seuil de probabilité 55 %. Pour comparer d’autres seuils (45 % / 60 % / 65 %), voir l’article n°19 (Seuils & stratégie).
Avant / Après : ce que disent les métriques
Lecture : la calibration est plus « juste » (Brier/LogLoss en baisse) et l’auto-config conserve un bon équilibre volume ↔ fiabilité malgré la hausse des matchs ≥55 %.
Par ligue : accepter la réalité, puis la compenser
Les ligues volatiles (ex. MLS, J.League) bénéficient le plus de la calibration locale et des seuils auto-configurés. Au lieu d’uniformiser les comportements, nous acceptons leurs spécificités et compensons via la pondération et les seuils.
👉 Consultez la page Résultats passés pour la réussite par ligue, mise à jour automatiquement.
Concrètement, pour vous
- Plus d’opportunités quand les ligues sont stables ; plus de prudence en période de drift.
- Probabilités plus honnêtes : 60 % signifie ~6/10 sur la durée (voir article 18).
- Seuils plus pertinents et cadre simple pour choisir votre équilibre volume ↔ précision (voir article 19).
Roadmap : apprentissage continu sous contrôle
La boucle quotidienne s’appuie sur le drift monitoring, l’auto-calibration par ligue et l’auto-config des paramètres. Pour le détail de cette boucle (sans fuite de futur), lisez l’article 20.
FAQ
Pourquoi publier un journal d’algorithme ?
La transparence crée la confiance. Nous montrons ce que nous changeons, pourquoi et comment nous mesurons l’impact.
Cette mise à jour modifie-t-elle les anciens résultats ?
Non. Les historiques restent tels quels et servent de base de comparaison publique.
Le modèle apprend-il en continu ?
Oui : validation temporelle, recalibration périodique, auto-config, avec no look-ahead.
Où suivre les prochaines évolutions ?
Sur cette série d’articles (17 → 21) et sur la page Résultats passés.
Conclusion
La version Q2 2025 renforce la fiabilité des probabilités et améliore le volume exploitable. En pratique : des prédictions plus stables, des seuils plus pertinents et une progression continue grâce au monitoring du drift.