
Cadre
Le mot “malédiction” attire l’attention, mais ce n’est pas une explication. Dans cet article, Bordeaux–OM sert de cas d’école : une série historique réelle, très forte narrativement, mais dangereuse à apprendre telle quelle dans un modèle de prédiction football.
Bordeaux–OM : pourquoi parle-t-on de “malédiction” ?
La raison est simple : l’Olympique de Marseille est resté sans victoire en championnat à Bordeaux pendant plus de quatre décennies. La série a été brisée le 7 janvier 2022, avec une victoire marseillaise 0–1 sur la pelouse des Girondins.
C’est le type de fait qui marque les supporters, les médias et les modèles trop naïfs. Pour un humain, c’est une histoire. Pour la data, c’est une série extrême. Pour une IA, c’est surtout une question : faut-il apprendre ce face-à-face comme un signal, ou le traiter comme un piège statistique ?
Sources publiques : la victoire 0–1 de l’OM à Bordeaux le 7 janvier 2022 est rapportée comme une première depuis 1977 ; plusieurs sources indiquent aussi 36 déplacements sans victoire avant le 37e réussi.
La vraie question : malédiction, hasard ou biais statistique ?
Quand les internautes cherchent “Bordeaux OM 44 ans”, “Marseille jamais gagné à Bordeaux” ou “malédiction Bordeaux Marseille”, ils cherchent rarement une formule mathématique. Ils veulent comprendre pourquoi une série aussi longue a pu exister.
La réponse honnête est moins spectaculaire qu’une superstition : une série longue peut naître de la variance, se prolonger par le contexte, puis être renforcée par la narration. Plus elle devient connue, plus elle influence la lecture du match : pression médiatique, prudence tactique, peur de répéter l’échec, attente du public, commentaires d’avant-match.
Mais pour une IA de prédiction football, cette narration n’est pas suffisante. Un modèle robuste doit distinguer trois niveaux : le fait historique, le signal statistique, et le risque de surapprentissage.
Chronologie simple : de 1977 à 2022
- 1977 : dernière victoire de Marseille à Bordeaux avant la longue série.
- Années 1980–2010 : la série se prolonge au fil des générations, des entraîneurs et des styles de jeu.
- Avant 2022 : le face-à-face devient un sujet médiatique en soi, presque indépendant du niveau réel des équipes.
- 7 janvier 2022 : Marseille gagne 0–1 à Bordeaux et met fin à la série.
- Après la rupture : la donnée change de statut. Elle n’est plus une série active, mais un cas d’étude historique.
Cette chronologie montre pourquoi le H2H brut est risqué : il mélange des matchs qui appartiennent à des contextes très différents. Les effectifs, les entraîneurs, la préparation, l’économie du football et même la pression médiatique n’ont rien de constant sur 44 ans.
Pourquoi le face-à-face brut peut piéger une prédiction football
Le H2H, ou historique face-à-face, est une information séduisante : elle est facile à comprendre, facile à commenter et très présente dans les articles d’avant-match. Pourtant, en modélisation, c’est souvent l’une des variables les plus dangereuses si elle est utilisée sans garde-fou.
Une série comme Bordeaux–OM pose quatre problèmes majeurs :
- Non-stationnarité : les matchs de 1985, 2005 et 2022 ne décrivent pas le même football.
- Petit échantillon : même une série longue en années reste limitée en nombre de matchs.
- Survie narrative : on retient la série parce qu’elle est spectaculaire, pas parce qu’elle se généralise.
- Confusion causalité/répétition : répéter un événement ne prouve pas qu’une cause stable existe.
Le piège : transformer “Marseille n’a pas gagné à Bordeaux depuis longtemps” en “Marseille ne peut pas gagner à Bordeaux”. C’est exactement le type de glissement qu’un modèle doit éviter.
Ce que la data peut tester — et ce qu’elle ne peut pas prouver
Une approche sérieuse ne part pas d’une conclusion mystique. Elle teste des hypothèses simples. Le but n’est pas de “prouver la malédiction”, mais de voir quelles explications résistent au contexte.
Les graphiques historiques peuvent aider à illustrer ces questions, en particulier si l’on compare les buts marqués par l’OM à Bordeaux à son niveau offensif extérieur moyen sur les mêmes saisons. Mais même dans ce cas, la conclusion doit rester prudente : on observe une sous-performance relative, pas une loi universelle.
Le point le plus intéressant : sous-performance de l’OM ou surperformance de Bordeaux ?
L’erreur classique consiste à dire : “Bordeaux avait quelque chose de spécial contre Marseille”. C’est possible, mais la question data la plus utile est légèrement différente : Marseille produisait-il moins que son niveau habituel à l’extérieur lorsqu’il jouait à Bordeaux ?
Cette formulation est plus propre pour un modèle, car elle compare l’OM à lui-même : son niveau extérieur moyen, son contexte de saison, sa dynamique offensive et la difficulté du déplacement. On ne compare pas aveuglément des générations entières de Bordeaux et Marseille.
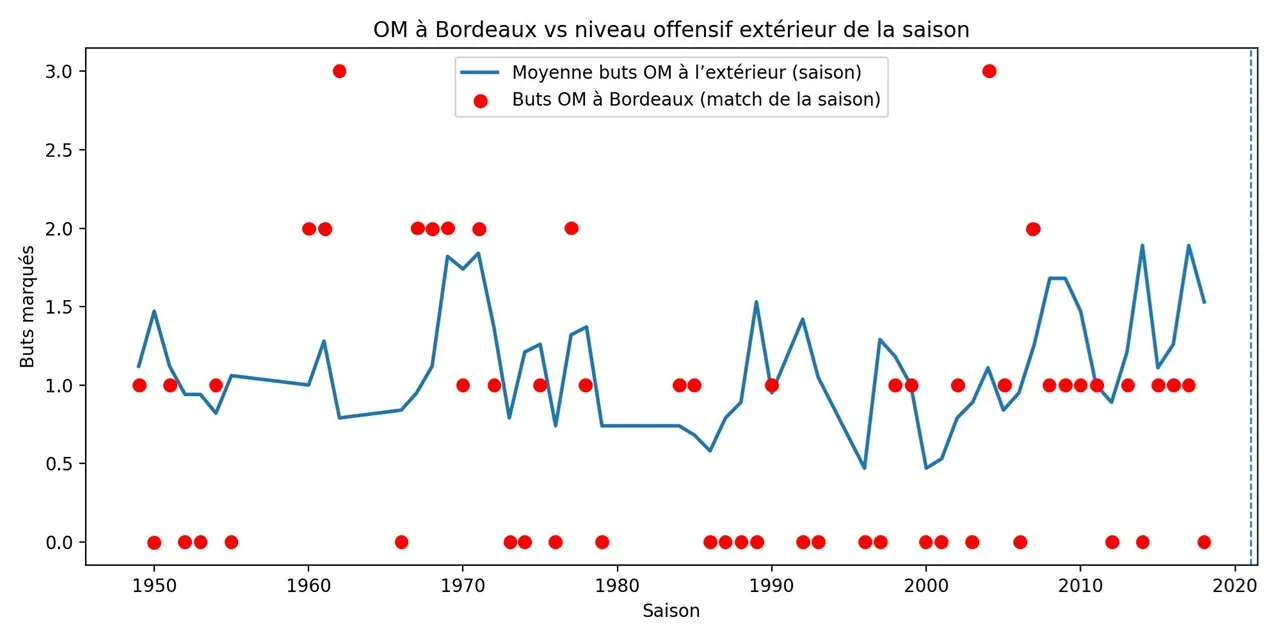
Lecture : si les performances à Bordeaux restent durablement sous le niveau extérieur habituel de l’OM, on peut parler de sous-performance contextuelle. Mais ce n’est pas encore une causalité : c’est un signal à encadrer.
La victoire de 2022 : pourquoi la rupture est instructive
La rupture de 2022 est importante parce qu’elle montre qu’une série spectaculaire peut s’arrêter d’un coup. Si la “malédiction” était une loi forte, elle ne disparaîtrait pas aussi simplement. En revanche, si la série était un mélange de variance, de contexte et de narration, sa rupture devient beaucoup moins mystérieuse.
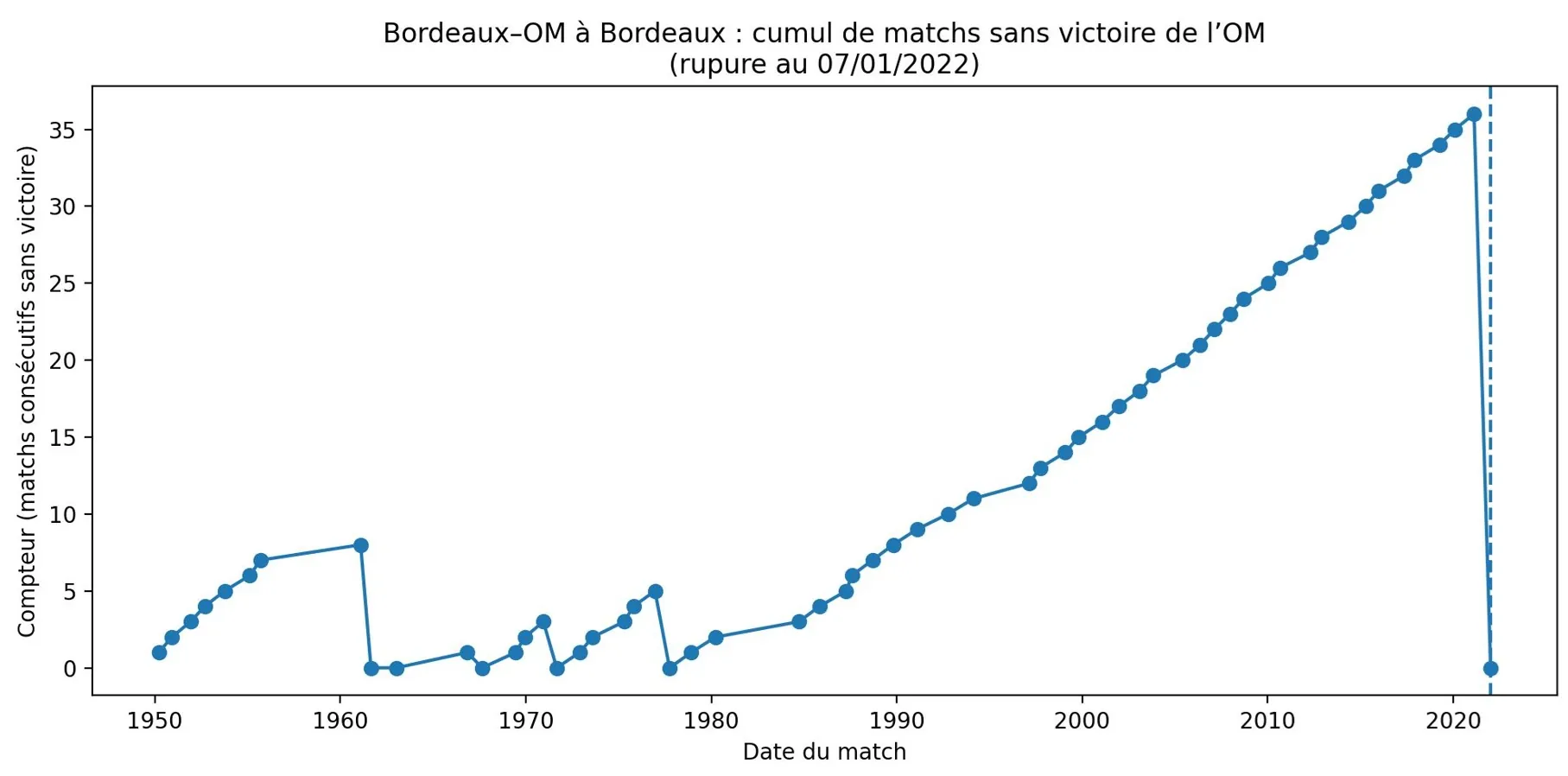
Lecture : le compteur est parlant pour raconter l’histoire, mais il ne suffit pas pour prédire. Le graphe du cumul montre la rareté ; l’analyse contextuelle dit si cette rareté mérite vraiment du poids dans un modèle.
Ce qu’une IA doit apprendre — et surtout ne pas apprendre
Dans un modèle de prédiction football, le bon comportement n’est pas de supprimer toute information H2H. Le bon comportement est de l’encadrer. Un face-à-face peut contenir un vrai signal stylistique : une équipe qui gêne souvent une autre, une opposition de profils, une difficulté structurelle à créer des occasions.
Mais Bordeaux–OM rappelle que le H2H doit être traité avec prudence :
- Pondération temporelle : les matchs anciens doivent peser beaucoup moins.
- Régularisation : une série rare ne doit pas provoquer une probabilité extrême.
- Contrôle par ligue : l’effet doit être replacé dans la structure de la compétition.
- Indice de confiance : si le signal est narratif mais peu robuste, la confiance doit rester prudente.
- Calibration : les probabilités publiées doivent rester honnêtes par rapport aux résultats observés.
C’est exactement la logique développée dans les articles sur l’indice de confiance, la calibration des probabilités et les séries de victoires et la régression vers la moyenne.
Pourquoi cette leçon vaut aussi pour les pages de championnat
Le cas Bordeaux–OM est spectaculaire parce qu’il concerne deux clubs français très connus. Mais le même raisonnement s’applique à chaque championnat : un historique face-à-face, une série longue ou une réputation de stade ne doivent jamais être lus sans contexte.
Pour une lecture plus opérationnelle, il faut relier le match à sa ligue : variance des nuls, avantage domicile, rythme de buts, fiabilité observée, profondeur d’historique.
- Pronostics Ligue 1 : contexte naturel pour Bordeaux–OM et les historiques français.
- Pronostics Ligue 2 : utile pour comprendre les séries dans des ligues plus instables.
- Pronostics Premier League : comparer les séries dans une ligue très médiatisée.
- Pronostics Liga, Serie A et Bundesliga : voir comment les structures de championnat changent la lecture du H2H.
- Pronostics Champions League : cas extrême où l’historique est souvent faible et très contextuel.
Guide pratique : comment lire un H2H avant un match ?
- Séparer le récent de l’ancien : les matchs très anciens racontent surtout une histoire, pas forcément le match à venir.
- Comparer au niveau saisonnier : une équipe sous-performe-t-elle vraiment contre cet adversaire ?
- Regarder le contexte de ligue : certains championnats produisent plus de nuls, d’upsets ou d’effet domicile.
- Vérifier la probabilité actuelle : le modèle voit-il un écart réel ou seulement une narration ?
- Lire l’indice de confiance : un H2H spectaculaire avec faible confiance doit être traité comme un risque, pas comme une preuve.
Sur Foresportia, le bon réflexe est de partir des matchs du jour, puis de vérifier les résultats passés, les marchés détaillés et les pages ligues concernées.
Conclusion : la “malédiction” est utile si elle apprend la prudence
Bordeaux–Marseille est un très bon article de data football parce qu’il parle à deux publics : les supporters qui se souviennent d’une série mythique, et les lecteurs data qui savent qu’une série extrême peut piéger un modèle.
La bonne conclusion n’est pas “les malédictions existent” ni “tout est hasard”. La bonne conclusion est plus utile : une série longue est un signal à tester, pas une vérité à recopier. C’est exactement ce qui distingue une lecture statistique responsable d’un simple commentaire de face-à-face.
FAQ rapide
Pourquoi parle-t-on de malédiction Bordeaux–OM ?
Parce que Marseille est resté plus de quatre décennies sans gagner en championnat à Bordeaux, jusqu’à la victoire 0–1 du 7 janvier 2022.
Combien de temps l’OM est-il resté sans gagner à Bordeaux ?
La série médiatique est généralement présentée comme une attente de 44 ans, depuis 1977 jusqu’à janvier 2022.
Le H2H est-il fiable pour prédire un match ?
Le H2H peut être informatif, mais il est dangereux s’il est utilisé brut. Il faut pondérer le récent, contextualiser la ligue et éviter de surapprendre des séries rares.
Une série historique doit-elle influencer une IA football ?
Oui, mais seulement de façon encadrée. Une série ancienne et spectaculaire doit surtout augmenter la prudence si elle n’est pas confirmée par des signaux actuels.
Top lectures du jour
Passe de ce cas d’école aux pages pratiques pour lire les matchs actuels.
Voir les matchs du jour